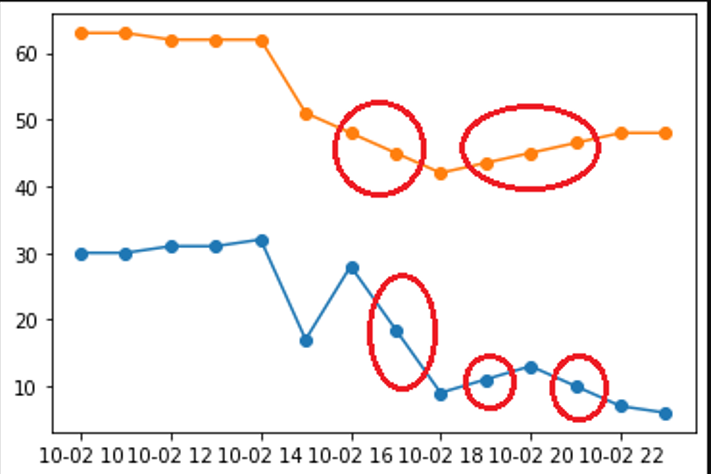
I would like to be able to plot the part of the data which had been interpolate-d(circled in red) with a different FMT.
My current idea was to plot 2 line, original and only the interpolate-d part of the data, with different FMT to differentiate the interpolate part making it seems as a singular line. But I'm having trouble extracting the data that have been interpolate-d and I'm not sure if my idea is currently viable or is there a simpler alternative to accomplish it.
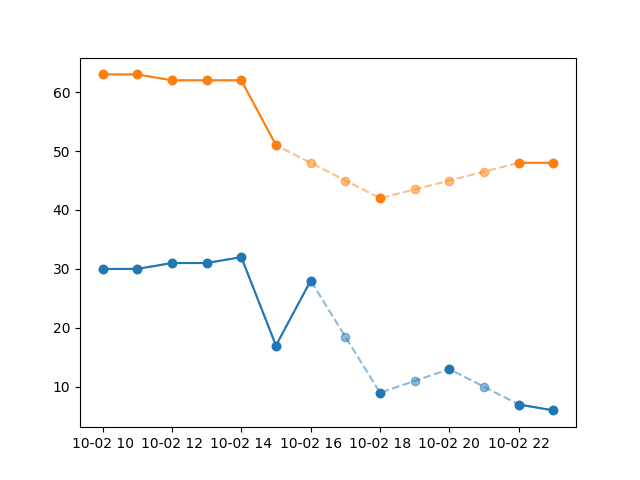
original data
Phoenix Chicago
datetime
2012-10-02 10:00:00 30.0 63.0
2012-10-02 11:00:00 30.0 63.0
2012-10-02 12:00:00 31.0 62.0
2012-10-02 13:00:00 31.0 62.0
2012-10-02 14:00:00 32.0 62.0
2012-10-02 15:00:00 17.0 51.0
2012-10-02 16:00:00 28.0 NaN
2012-10-02 17:00:00 NaN NaN
2012-10-02 18:00:00 9.0 42.0
2012-10-02 19:00:00 NaN NaN
2012-10-02 20:00:00 13.0 NaN
2012-10-02 21:00:00 NaN NaN
2012-10-02 22:00:00 7.0 48.0
2012-10-02 23:00:00 6.0 48.0
plt.plot(df[['Phoenix','Chicago']], marker = 'o')
plt.show()
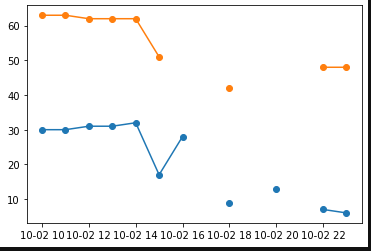
After interpolate
Phoenix Chicago
datetime
2012-10-02 10:00:00 30.0 63.0
2012-10-02 11:00:00 30.0 63.0
2012-10-02 12:00:00 31.0 62.0
2012-10-02 13:00:00 31.0 62.0
2012-10-02 14:00:00 32.0 62.0
2012-10-02 15:00:00 17.0 51.0
2012-10-02 16:00:00 28.0 48.0
2012-10-02 17:00:00 18.5 45.0
2012-10-02 18:00:00 9.0 42.0
2012-10-02 19:00:00 11.0 43.5
2012-10-02 20:00:00 13.0 45.0
2012-10-02 21:00:00 10.0 46.5
2012-10-02 22:00:00 7.0 48.0
2012-10-02 23:00:00 6.0 48.0
df.interpolate(inplace = True)
plt.plot(df[['Phoenix','Chicago']], marker = 'o')
plt.show()
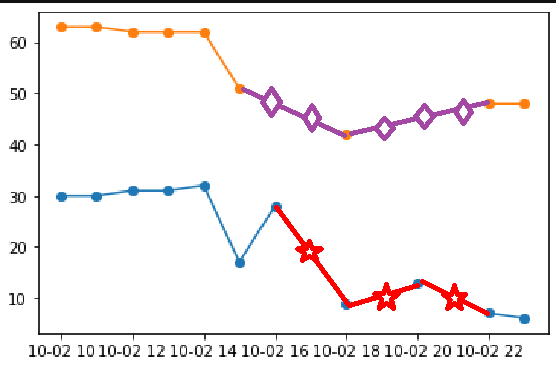
Rough Idea of what i'm trying to achieve
CodePudding user response:
You can use 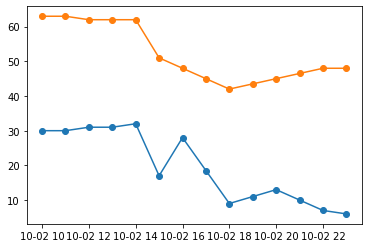
PS. Data for reproduction:
df = pd.DataFrame({"datetime": pd.period_range(start='2012-10-02 10:00:00', end='2012-10-02 23:00:00', freq='H').to_timestamp(),
"Phoenix": [30., 30., 31., 31., 32., 17., 28., np.nan, 9., np.nan, 13., np.nan, 7., 6.],
"Chicago": [63., 63., 62., 62., 62., 51., np.nan, np.nan, 42., np.nan, np.nan, np.nan, 48., 48.]})\
.set_index("datetime")
CodePudding user response:
Since matplotlib omits missing data (which is usually considered a problem), we can use this fact here and simply plot the original data over the interpolated data:
from matplotlib import pyplot as plt
import pandas as pd
#recreate your data
from io import StringIO
data = """datetime Phoenix Chicago
2012-10-02 10:00:00 30.0 63.0
2012-10-02 11:00:00 30.0 63.0
2012-10-02 12:00:00 31.0 62.0
2012-10-02 13:00:00 31.0 62.0
2012-10-02 14:00:00 32.0 62.0
2012-10-02 15:00:00 17.0 51.0
2012-10-02 16:00:00 28.0 NaN
2012-10-02 17:00:00 NaN NaN
2012-10-02 18:00:00 9.0 42.0
2012-10-02 19:00:00 NaN NaN
2012-10-02 20:00:00 13.0 NaN
2012-10-02 21:00:00 NaN NaN
2012-10-02 22:00:00 7.0 48.0
2012-10-02 23:00:00 6.0 48.0"""
df = pd.read_csv(StringIO(data), sep = "\s{2,}", engine="python", parse_dates=["datetime"], na_values = "NaN")
df = df.set_index("datetime")
#interpolate and plot the interpolated data with transparency and dashed lines
dfint = df.interpolate()
plt.plot(dfint[['Phoenix','Chicago']], marker = 'o', alpha=0.5, ls="--")
#reset color cycle, so that the colors match
plt.gca().set_prop_cycle(None)
#plot again with missing data
plt.plot(df[['Phoenix','Chicago']], marker = 'o')
plt.show()
Sample output: