I have a problem in which i have a CSV file with StartDate and EndDate, Consider 01-02-2020 00:00:00 and 01-03-2020 00:00:00
And I want a python program that finds the dates in between the dates and append in next rows like

So here instead of dot , it should increment Startdate and keep End date as it is.
import pandas as pd
df = pd.read_csv('MyData.csv')
df['StartDate'] = pd.to_datetime(df['StartDate'])
df['EndDate'] = pd.to_datetime(df['EndDate'])
df['Dates'] = [pd.date_range(x, y) for x , y in zip(df['StartDate'],df['EndDate'])]
df = df.explode('Dates')
df
So for example , if i have StartDate as 01-02-2020 00:00:00 and EndDate as 05-02-2020 00:00:00
As result i should get
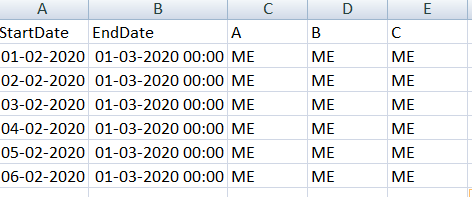
All the result DateTime should be in same format as in MyData.Csv StartDate and EndDate
Only the StartDate will change , rest should be same
I tried doing it with date range. But am not getting any result. Can anyone please help me with this.
Thanks
CodePudding user response:
My two cents: a very simple solution based only on functions from pandas:
import pandas as pd
# Format of the dates in 'MyData.csv'
DT_FMT = '%m-%d-%Y %H:%M:%S'
df = pd.read_csv('MyData.csv')
# Parse dates with the provided format
for c in ('StartDate', 'EndDate'):
df[c] = pd.to_datetime(df[c], format=DT_FMT)
# Create the DataFrame with the ranges of dates
date_df = pd.DataFrame(
data=[[d] list(row[1:])
for row in df.itertuples(index=False, name=None)
for d in pd.date_range(row[0], row[1])],
columns=df.columns.copy()
)
# Convert dates to strings in the same format of 'MyData.csv'
for c in ('StartDate', 'EndDate'):
date_df[c] = date_df[c].dt.strftime(DT_FMT)
If df is:
StartDate EndDate A B C
0 2020-01-02 2020-01-06 ME ME ME
1 2021-05-15 2021-05-18 KI KI KI
then date_df will be:
StartDate EndDate A B C
0 01-02-2020 00:00:00 01-06-2020 00:00:00 ME ME ME
1 01-03-2020 00:00:00 01-06-2020 00:00:00 ME ME ME
2 01-04-2020 00:00:00 01-06-2020 00:00:00 ME ME ME
3 01-05-2020 00:00:00 01-06-2020 00:00:00 ME ME ME
4 01-06-2020 00:00:00 01-06-2020 00:00:00 ME ME ME
5 05-15-2021 00:00:00 05-18-2021 00:00:00 KI KI KI
6 05-16-2021 00:00:00 05-18-2021 00:00:00 KI KI KI
7 05-17-2021 00:00:00 05-18-2021 00:00:00 KI KI KI
8 05-18-2021 00:00:00 05-18-2021 00:00:00 KI KI KI
Then you can save back the result to a CSV file with the to_csv method.
CodePudding user response:
Does something like this achieve what you want?
from datetime import datetime, timedelta
date_list = []
for base, end in zip(df['StartDate'], df['EndDate']):
d1 = datetime.strptime(base, "%d-%m-%Y %H:%M:%S")
d2 = datetime.strptime(end, "%d-%m-%Y %H:%M:%S")
numdays = abs((d2 - d1).days)
basedate = datetime.strptime(base, "%d-%m-%Y %H:%M:%S")
date_list = [basedate - timedelta(days=x) for x in range(numdays)]
df['Dates'] = date_list
CodePudding user response:
Actually the code you provided is working for me. I guess the only thing you need to change is the date formatting in reading and writing operations to make sure that is consistent with your requirements. In particular, you should leverage the dayfirst argument when reading and date_format when writing the output file. A toy example below:
Toy data
| StartDate | EndDate | A | B | C |
|---|---|---|---|---|
| 01-02-2020 00:00:00 | 06-02-2020 00:00:00 | ME | ME | ME |
| 01-04-2020 00:00:00 | 04-04-2020 00:00:00 | PE | PE | PE |
Sample code
import pandas as pd
s_dates = ['01-02-2020', '01-03-2020']
e_dates = ['01-04-2020', '01-05-2020']
df = pd.read_csv('dataSO.csv', parse_dates=[0,1], dayfirst=True)
cols = df.columns
df['Dates'] = [pd.date_range(x, y) for x , y in zip(df['StartDate'],df['EndDate'])]
df1 = df.explode('Dates')[cols]
df1.to_csv('resSO.csv', date_format="%d-%m-%Y %H:%M:%S", index=False)
And the output is what you described except for the fact that StartDate is also in datetime format. Does this answer you question?