I have the following data structure:
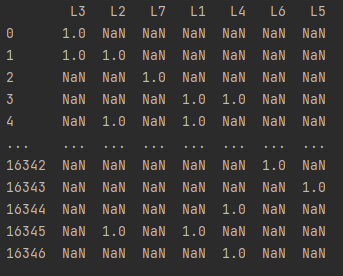
Each row represents one annotation. If the user labeled the data with labels 2 and 3 (see second row aka row index 1) than the dataset would be 1 1 0 0 0 0 0.
I would like to make a heatmap out of this, in order to see which labels are closely annotated. The resulting df i believe should be 7x7.(i've tried with np.corrcoef, i've tried pivoting the data, it might be just that i'm not asking the question right.)
Any help is appreciated, thanks!
The first 5 rows of data:
df = [{'L3': 1},
{'L2': 1, 'L3': 1},
{'L7': 1},
{'L1': 1, 'L4': 1},
{'L1': 1, 'L2': 1}]
df = pd.DataFrame(df)
CodePudding user response:
Use corr after replacing nan by 0 else you get a matrix filled with nan:
corr = df.fillna(0).corr()
print(corr)
plt.colormesh(corr)
plt.show()
# Output
L1 L2 L3 L4 L5 L6 L7
L1 1.000000 0.010929 -0.011707 -0.000469 -0.024428 -0.004918 0.033066
L2 0.010929 1.000000 -0.028859 -0.012876 -0.000667 0.009042 -0.017563
L3 -0.011707 -0.028859 1.000000 -0.033609 0.017446 0.036202 0.018763
L4 -0.000469 -0.012876 -0.033609 1.000000 -0.035363 -0.009639 0.038593
L5 -0.024428 -0.000667 0.017446 -0.035363 1.000000 0.007565 -0.045324
L6 -0.004918 0.009042 0.036202 -0.009639 0.007565 1.000000 -0.009466
L7 0.033066 -0.017563 0.018763 0.038593 -0.045324 -0.009466 1.000000
For a quick view, you can use matplotlib but if you want to produce beautiful output, I recommend you to install and use seaborn
Setup a MRE
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
N = 2000
np.random.seed(2022)
df = pd.DataFrame(np.random.choice([np.NaN, 1], (N, 7), p=[.7, .3]),
columns=[f'L{i}' for i in range(1, 8)])