let say I have a pandas data frame and already grouped as
grp=df.groupby(['a','b' ]).sum()
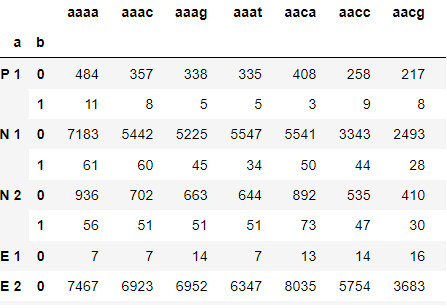
now I would like to calculate for every group a , the percentage of b for each column ,
for example: P1, aaaa = 11/484, P1, aaac = 8/357, N1, aaaa = 61/7183 so on ....
Reproducible grouped data
pd.DataFrame({'aaaa': {('P 1', 0): 484,('P 1', 1): 11,}})

CodePudding user response:
You can do:
grp.loc[(slice(None), 1),:].droplevel(1)/grp.loc[(slice(None), 0),:].droplevel(1)
In practice whith grp.loc[(slice(None), 1),:] and grp.loc[(slice(None), 0),:] I extract only the rows with b==1 and b==0 (try yourself and see the output); after that I need to remove the b level (.droplevel(1)) to make these two objects have the same index (the columns are already shared); finally I divided this two matrices with / (now I can do it because now they have same index and columns). Hope it is clear :)
CodePudding user response:
You can use xs to a select particular level of a MultiIndex:
out = df.xs(1, level=1) / df.xs(0, level=1)
Output:
aaaa
P 1 0.022727