I've been learning Haskell recently and came across something I don't quite understand: the parameters of a lambda function.
In the Learn You a Haskell for Great Good book, chap. 5, there are the following two functions:
elem' :: (Eq a) => a -> [a] -> Bool
elem' y ys = foldr (\x acc -> if x == y then True else acc) False ys
reverse' :: [a] -> [a]
reverse' = foldl (\acc x -> x : acc) []
In the first function, the accumulator is listed as the lambda's second parameter, but then is the first to follow the lambda for foldl, which I took to mean it would be the first, not the second, thus, defying expectations.
Whereas, in the second function, it follows expectations, showing up as the lambda's first parameter, making the list that reverse' takes as a parameter the second for the lambda.
I tested both functions and they work as expected. I also noticed that one function involves a right fold and the other a left fold, but I'm not sure why that would alter the meaning of the parameters.
QUESTION: Can someone explain what I'm missing? Why are the parameters seeming to swap places?
CodePudding user response:
foldl and foldr expect the accumulating function to have different formats. The two functions have the following types:
foldl :: Foldable t => (b -> a -> b) -> b -> t a -> b
foldr :: Foldable t => (a -> b -> b) -> b -> t a -> b
You're correct that in foldr, the accumulator is the second argument, and in foldl it's the left.
While this may seem unintuitive, it may help to think of foldl and foldr in terms of how they associate values in a list, the following images come from the "fold" page on the Haskell wiki:
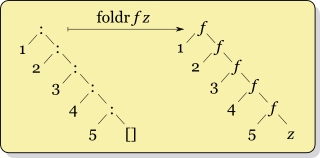
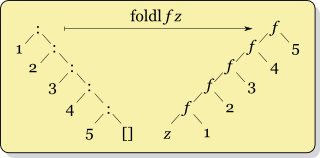
Treating the natural order of the list as left to right: In foldr, the accumulator starts at the right hand side of the list, so it's natural that it's the second argument, while in foldl, the opposite is true.
CodePudding user response:
It is just a convention that the accumulator in foldr is the second argument, and in foldl it is the first argument.
Why was this convention chosen?
The first reason was answered by @Joe.
accis the folded part of the list. Infoldlit's left part but infoldrit's right part. So it's natural to provideaccas left operand (the first argument) to folding operator infoldland as right operand (the second argument) to folding operator infoldr.foldlshould iterate over all the elements in the provided list, whilefoldrshould not. You can provide folding operator to thefoldrwhich can skip rest of elements in the list. The first example does that. The second argumentaccin thefoldris thing which is not computed yet, it hold folding the rest of elements. And if you skip it in your folding operator it never be computed. In your example, ifx == yyou just "return"True(and skip rest elements), else you "return"accwhich force to evaluate the next element in the list. So,foldrworks lazyly, butfoldlworks strictly.In Haskell is another convention. When operator can works lazyly then it usually have the first argument with strict semantic and the second with non strict. For example:
&&,||are this sort of operators.False && undefined => False True || undefined => TrueFolding operator in your the first example is lazy too.
(\x acc -> if x == y then True else acc) y undefined => TrueAnd it can be rewrite in terms of
||like this:(\x acc -> x == y || acc)
Combining above reasons together we have what we have :-)