I want to populate values of df2['VALUE'] in a new column in df1 df1['New'] when category and location match for both dataframes.
When
df1['category'] = df2['CATEGORY'] AND df1['location'] = df2['LOCATION']
populate values of df2['VALUE'] into a new row in df1 so that using df1['v1'] I can calculate df1['calculatedfield'] = df1['v1']/df1['new']
df1
| category | location | type | v1 |
|---|---|---|---|
| A | loc1 | 1 | 2 |
| A | loc1 | 2 | 4 |
| A | loc2 | 1 | 6 |
| A | loc2 | 2 | 8 |
| B | loc1 | 1 | 10 |
| B | loc1 | 2 | 12 |
| B | loc2 | 1 | 14 |
| B | loc2 | 2 | 16 |
df2
| CATEGORY | LOCATION | VALUE |
|---|---|---|
| A | loc1 | 50 |
| A | loc2 | 30 |
| B | loc1 | 70 |
| B | loc2 | 90 |
output
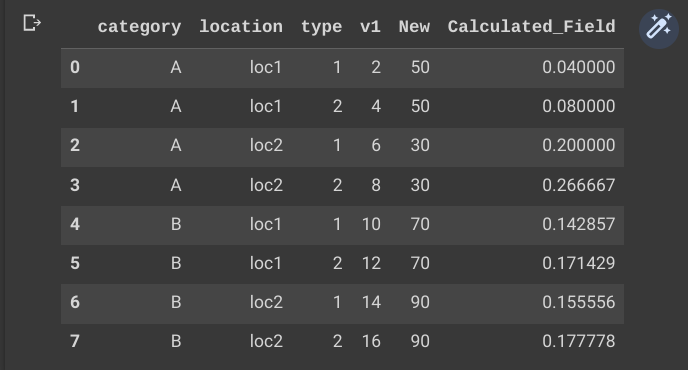
| category | location | type | v1 | new(df2['VALUE']) | calculatedfield(v1/new) |
|---|---|---|---|---|---|
| A | loc1 | 1 | 2 | 50 | 0.04 |
| A | loc1 | 2 | 4 | 50 | 0.08 |
| A | loc2 | 1 | 6 | 30 | 0.2 |
| A | loc2 | 2 | 8 | 30 | 0.27 |
| B | loc1 | 1 | 10 | 70 | 0.14 |
| B | loc1 | 2 | 12 | 70 | 0.17 |
| B | loc2 | 1 | 14 | 90 | 0.16 |
| B | loc2 | 2 | 16 | 90 | 0.18 |
df1 has more rows than df2, that is why I didn't go with joining the two dataframes. I need to populate df2['new'] with the values from df2['VALUE'] wherever the combination of category and location come up and regardless of the value of df2['type']. I can't drop rows.
I tried
df1['New'] = np.where((df1['category'] == df2['CATEGORY']) & (df1['location'] == df2['location']), df2['VALUE'], None)
and this came up:
ValueError: Can only compare identically-labeled Series objects
CodePudding user response:
You can use pandas.set_index() function to create a multiIndex dataframe for obtaining values from df2 and use the pandas.reset.index() to reset the dataframe. Please see below my sample code. I have replicated your dataframes df1 and df2.
code:
import pandas as pd
data1 = {'category': ['A', 'A', 'A', 'A','B', 'B', 'B', 'B'],
'location': ['loc1', 'loc1', 'loc2', 'loc2','loc1', 'loc1', 'loc2', 'loc2'],
'type': [1,2,1,2,1,2,1,2,],
'v1': [2,4,6,8,10,12,14,16]}
data2 = {'category': ['A', 'A','B', 'B'],
'location': ['loc1', 'loc2', 'loc1','loc2'],
'VALUE': [50,30,70,90]}
df1 = pd.DataFrame(data1)
df2 = pd.DataFrame(data2)
df_temp = df1.set_index(['category','location'])
df_temp['New'] = df2.set_index(['category','location'])['VALUE']
df1 = df_temp.reset_index()
df1['Calculated_Field'] = df1['v1']/df1['New']
df1
Output:
References:
https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.set_index.html