I have a table as follows:
| ID | ACTIVE_STATUS | DATE |
|---|---|---|
| 45 | TRUE | 2022-06-12 |
| 45 | TRUE | 2022-06-13 |
| 45 | FALSE | 2022-07-01 |
| 36 | TRUE | 2022-08-01 |
| 36 | FALSE | 2022-08-02 |
| 36 | FALSE | 2022-08-14 |
| 36 | TRUE | 2022-08-15 |
| 14 | TRUE | 2022-03-25 |
| 14 | TRUE | 2022-03-28 |
| 14 | TRUE | 2022-03-29 |
I would like to remove rows from the table where within each ID group, if the current ACTIVE_STATUS value is the same as the value in the previous row, then remove the current row (Basically I am keeping the rows where the ACTIVE_STATUS shows a change for each ID group).
For example for ID 45, the active status was TRUE on 2022-06-12 and stayed TRUE until it became FALSE on 2022-07-01 so I would delete the row where the status is TRUE for date 2022-06-13 since there is no change in status between that and the previous row. I currently have the data ordered by DATE per ID group. I would like the output to look like
| ID | ACTIVE_STATUS | DATE |
|---|---|---|
| 45 | TRUE | 2022-06-12 |
| 45 | FALSE | 2022-07-01 |
| 36 | TRUE | 2022-08-01 |
| 36 | FALSE | 2022-08-02 |
| 36 | TRUE | 2022-08-15 |
| 14 | TRUE | 2022-03-25 |
I currently have:
SELECT ID, ACTIVE_STATUS, DATE
FROM MY_TABLE
GROUP BY ID, ACTIVE_STATUS, DATE
ORDER BY DATE;
But I am not sure how to use lag() to achieve this or a partition? Any help would be great!
CodePudding user response:
Using 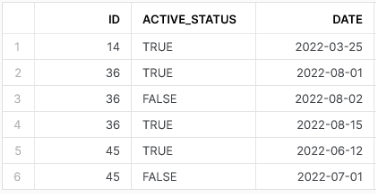
Before filtering:
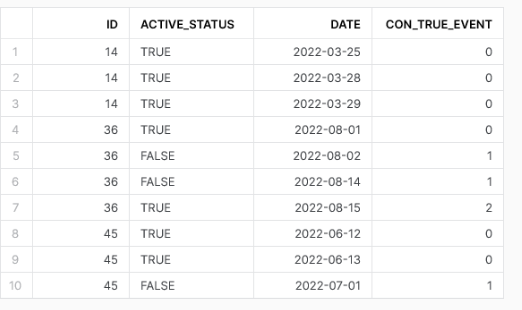
CodePudding user response:
Here's how you would use lag. You can keep the lag in the select to see what it's doing. Qualify is to Window Function what Having is to Group By.
select *
from your_table
qualify lag(active_status) over(partition by id order by date) <> active_status or
lag(active_status) over(partition by id order by date) is null
If your team is familiar with null-safe equality operators, you could use is distinct from and simplify that to
select *
from your_table
qualify lag(active_status) over(partition by id order by date) is distinct from active_status