I have the dataframe that has employees, and their level.
import pandas as pd
d = {'employees': ["John", "Jamie", "Ann", "Jane", "Kim", "Steve"], 'Level': ["A/Ba", "C/A", "A", "C", "Ba/C", "D"]}
df = pd.DataFrame(data=d)
How do I add a new column that measures the number of employees with the same levels. For example, John would have 3 as there are 2 A's (Jamie and Ann) and one other Ba (Kim). Note it does not count the employee in this case John level(s) to that count.
My goal is for the end dataframe to be this.
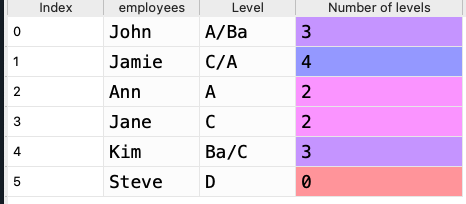
CodePudding user response:
Try this:
df['Number of levels'] = df['Level'].str.split('/').explode().map(df['Level'].str.split('/').explode().value_counts()).sub(1).groupby(level=0).sum()
Output:
>>> df
employees Level Number of levels
0 John A/Ba 3
1 Jamie C/A 4
2 Ann A 2
3 Jane C 2
4 Kim Ba/C 3
5 Steve D 0
CodePudding user response:
exploded = df.Level.str.split("/").explode()
counts = exploded.groupby(exploded).transform("count").sub(1)
df["Num Levels"] = counts.groupby(level=0).sum()
We first explode the "Level" column by splitting over "/" so we can reach to each level:
>>> exploded = df.Level.str.split("/").explode()
>>> exploded
0 A
0 Ba
1 C
1 A
2 A
3 C
4 Ba
4 C
5 D
Name: Level, dtype: object
We now need counts of each element in this series so we group by itself and transform by counts:
>>> exploded.groupby(exploded).transform("count")
0 3
0 2
1 3
1 3
2 3
3 3
4 2
4 3
5 1
Name: Level, dtype: int64
Since it counts elements themselves but you look at other places, we subtract 1 to get counts:
>>> counts = exploded.groupby(exploded).transform("count").sub(1)
>>> counts
0 2
0 1
1 2
1 2
2 2
3 2
4 1
4 2
5 0
Name: Level, dtype: int64
Now, we need to "come back", and the index is our helper for that; we group by it (level=0 means that) and sum the counts thereof:
>>> counts.groupby(level=0).sum()
0 3
1 4
2 2
3 2
4 3
5 0
Name: Level, dtype: int64
This is the end result and is assigned to df["Num Levels"].
to get
employees Level Num Levels
0 John A/Ba 3
1 Jamie C/A 4
2 Ann A 2
3 Jane C 2
4 Kim Ba/C 3
5 Steve D 0
This is all writable in "1 line" but it may hinder readability and further debuggings!
df["Num Levels"] = (df.Level
.str.split("/")
.explode()
.pipe(lambda ex: ex.groupby(ex))
.transform("count")
.sub(1)
.groupby(level=0)
.sum())