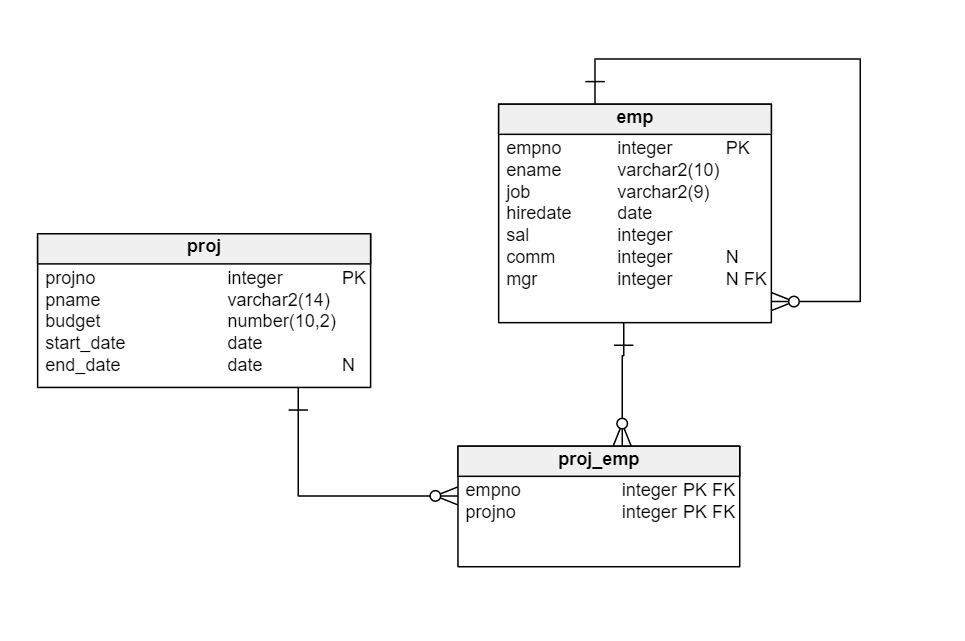
Given entity-relationship diagram like this, how do I complete the task that I typed out in the title?
I know that I need to create some subquery (correlated perhaps) but I just can't wrap my mind around this as examples like this haven't really been taught on the course.
I also cannot find any examples similiar to this one on the Internet, only simple correlated subquery related stuff (Maybe this one is also simple and I just can't notice something very obvious lol)
Help would be appreciated so I can get the general idea on how it should be done :)
In case the task description is not clear - emp has "job" field which has values like 'MANAGER', 'CLERK', 'ANALYST' and we want to show in which project worked the most of people having that job. Possible output:
job pname
MANAGER PROJ1
CLERK PROJ3
ANALYST PROJ2
CodePudding user response:
From my interpretation of the question, you should be able to use an aggregate function to get the number of people that were assigned to a job. The query you use could look something like this:
select projNo, count(empNo) 'Number of People on Job' from proj_emp group by projNo;
I have created an example on this SQL Fiddle, you can find that here.
If you wanted to show some more detail about a project, then you will just have to do a simple table join, or similar
CodePudding user response:
From what I see, Job should be normalized into it's own table (jobno, jobname), but given what you have, I think something like the following might work.
SELECT J.job, TP.pname, TP.emp_count
FROM (
SELECT DISTINCT E.job FROM emp E)
) J
CROSS APPLY (
SELECT TOP 1 P.pname, COUNT(*) AS emp_count
FROM emp E
JOIN proj_emp PE ON PE.empno = E.empno
JOIN proj P ON p.projno = PE.projno
WHERE E.job = J.job
GROUP BY P.pname
ORDER BY COUNT(*) DESC
) TP
If you need additional project fields, you would need to add them to the selects and the GROUP BY.
The above does not account for ties and will pick one of the tying project arbitrarily. Expanding the ORDER BY can make this less arbitrary. To return all tying projects would require more work. One approach would be for one CROSS APPLY to calculate the MAX(COUNT(*)) for projects associated with a given job, and a second retrieving the project information subject to a HAVING COUNT(*) = previously_calculated_max.
There may be a better way to do this using windowing functions, but that is not my expertise. Others may have suggestions along those lines.
ADDENDUM: Here is a query using windowing functions
SELECT A.job, A.pname, A.emp_count
FROM (
SELECT E.job, P.pname, COUNT(*) AS emp_count, MAX(COUNT(*)) OVER(PARTITION BY E.job) AS max_count
FROM proj P
JOIN proj_emp PE ON PE.projno = P.projno
JOIN emp E ON E.empno = PE.empno
GROUP BY E.job, P.pname
) A
WHERE A.emp_count = A.max_count;