I followed the example below, and all is going well.
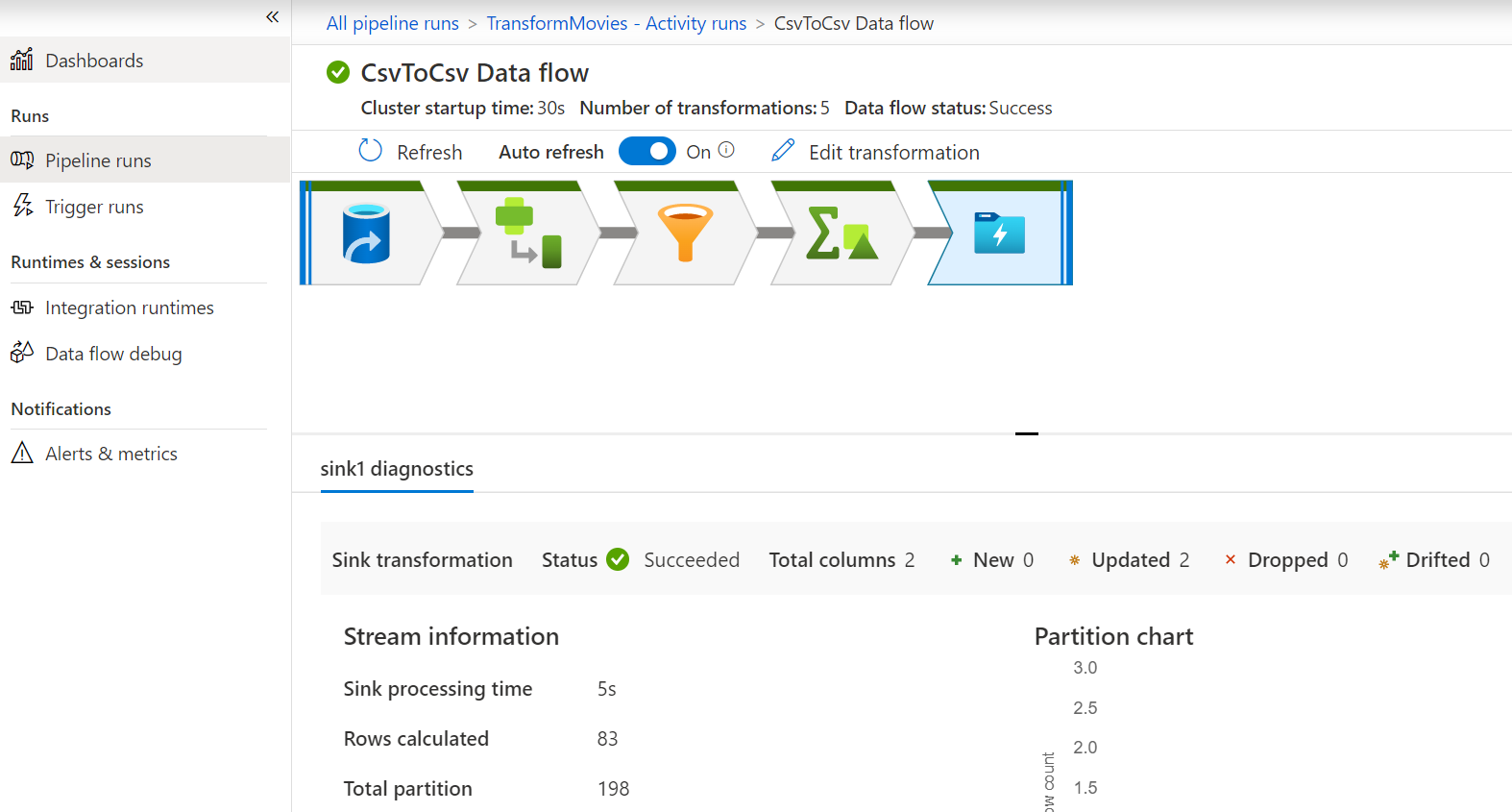
Below is the output. Please note that the total number of files is 77, not 83, not 1.
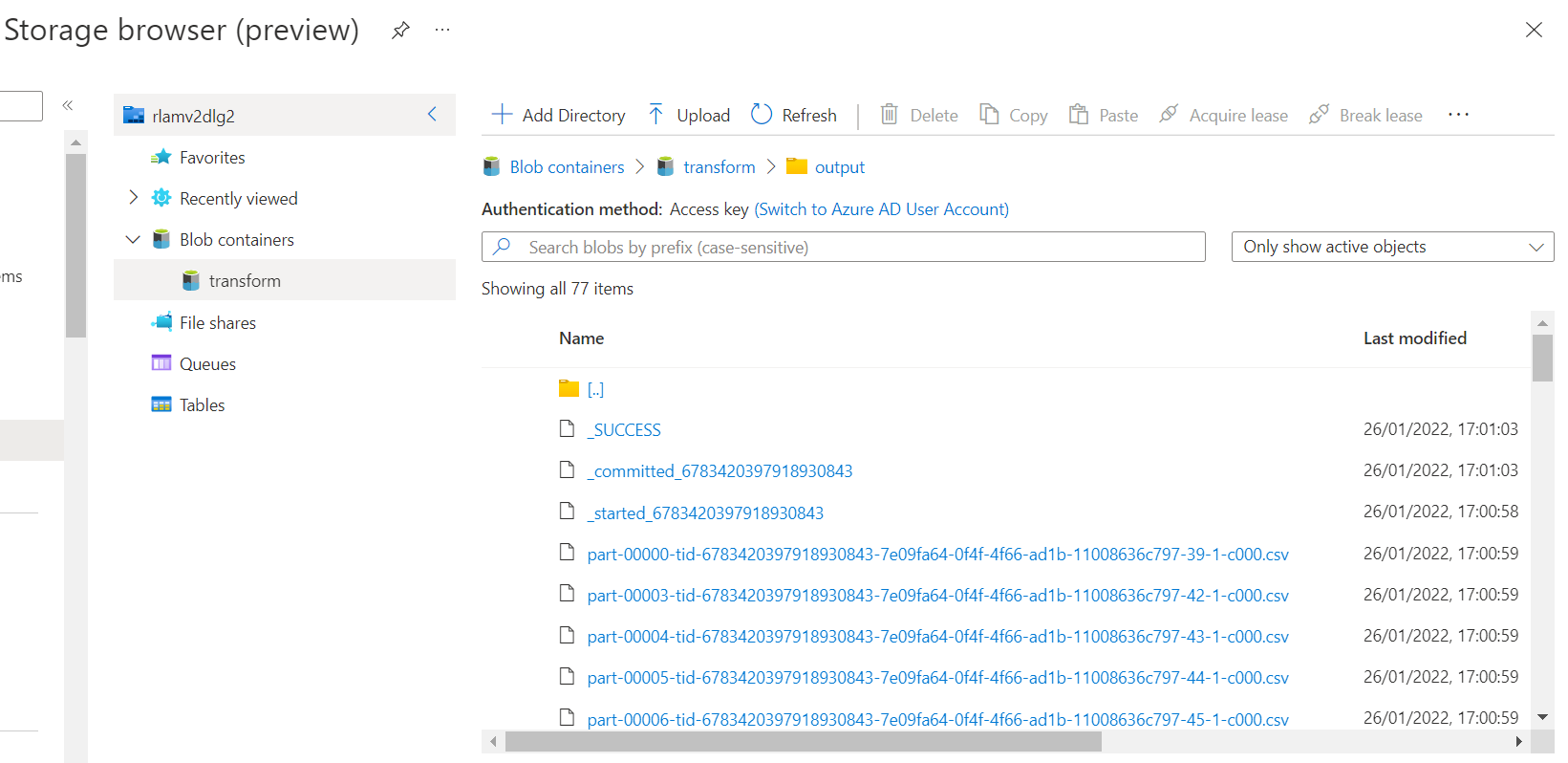
Question:: Is it correct to have so many csv files (77 items)?
Question:: How to combine all files into one file without slowing down the process?
I can create one file by following the link below, which warns of slowing down the process.
CodePudding user response:
The number of files generated from the process is dependent upon a number of factors. If you've set the default partitioning in the optimize tab on your sink, that will tell ADF to use Spark's current partitioning mode, which will be based on the number of cores available on the worker nodes. So the number of files will vary based upon how your data is distributed across the workers. You can manually set the number of partitions in the sink's optimize tab. Or, if you wish to name a single output file, you can do that, but it will result in Spark coalescing to a single partition, which is why you see that warning. You may find it takes a little longer to write that file because Spark has to coalesce existing partitions. But that is the nature of a big data distributed processing cluster.