I've looked at 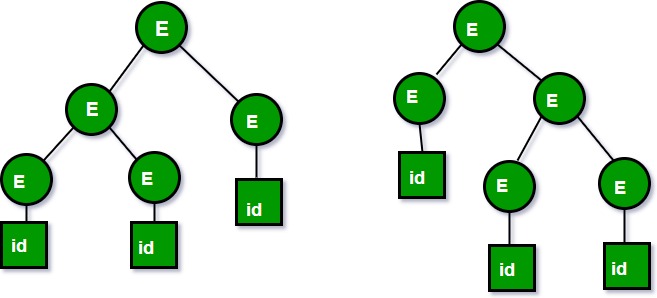
How can I go about generating all valid parsings of a string in Python given an ambiguous grammar?
To be clear, I don't care too much about the format of the input and output, as long as it can take in a grammar and a string and output all the valid parsings of that string using that grammar.
CodePudding user response:
Depending on how complicated your grammar is, you can probably just implement it yourself. Most libraries optimize to help with ambiguity, but if you want all the options, you can just do a simple recursion:
import abc
class Rule(metaclass=abc.ABCMeta):
@abc.abstractmethod
def parse(self, data):
"""Returns a generator of (result, remaining) tuples.
Parses data and returns all possible tuples of result (of parsing so far)
and remaining (data to be parsed). **Result must be a list**
"""
raise NotImplementedError()
class Node:
"""A tree node we can nicely print"""
def __init__(self, name, *values):
self.name = name
self.values = list(values)
def __repr__(self) -> str:
return str(self)
def __str__(self):
return f'{self.name}({",".join(str(v) for v in self.values)})'
class Literal(Rule):
"""A literal which we expect to find as is in the input."""
def __init__(self, value, *, name='Literal'):
self.value = value
self.name = name
def parse(self, data):
if not data:
return
if data[0] == self.value:
yield ([Node(self.name, self.value)], data[1:])
class Sequence(Rule):
"""A sequence of one-or-more rules to find in the input."""
def __init__(self, *rules, name='Sequence'):
self.rules = list(rules)
self.name = name
def recursive_parse_helper(self, next_rules, data):
if len(next_rules) == 1:
yield from next_rules[0].parse(data)
return
for result, more_data in next_rules[0].parse(data):
for remaining_result, remaining_data in self.recursive_parse_helper(next_rules[1:], more_data):
yield ([Node(self.name, *(result remaining_result))], remaining_data)
def parse(self, data):
yield from self.recursive_parse_helper(self.rules, data)
class OneOf(Rule):
"""A list of one-or-more rules that can be used to match the input."""
def __init__(self, *rules):
self.rules = list(rules)
def parse(self, data):
for rule in self.rules:
yield from rule.parse(data)
def parse(rule, data):
"""Parse the input until no more data is remaining. Return only full matches."""
for result, remaining in rule.parse(data):
if remaining:
for more_results in parse(rule, remaining):
yield result more_results
else:
yield result
And this works nicely:
E0 = Literal('id', name='E')
E = OneOf(Sequence(E0, E0), E0)
> list(parse(E, ['id', 'id', 'id']))
[[Sequence(E(id),E(id)), E(id)],
[E(id), Sequence(E(id),E(id))],
[E(id), E(id), E(id)]]
CodePudding user response:
One option is to keep a running list of the tokens that are being built up into abstract syntax trees, per the rules of the grammar. The algorithm can work in two parts:
- A token is read in and pushed to each list that is storing the AST being built up.
- The grammar rules are run against each sublist, spinning off subsequent potential matches.
Using a dictionary to define the grammar:
grammar = [
('E', {'op':'or',
'left':{'op':'and', 'left':'E', 'right':'E'},
'right':'id'
}
)
]
src = 'id id id'
def matches(name, pattern, tree):
if not tree:
return tree, None, 0
if isinstance(pattern, str):
if tree[-1]['name'] == pattern:
return tree[:-1], {'name':name, 'value':tree[-1]} if 'value' not in tree[-1] else tree[-1], 1
return tree, None, 0
if pattern['op']=='or':
if (m:=matches(name, pattern['right'], tree))[-1] or (m:=matches(name, pattern['left'], tree))[-1]:
return m
return tree, None, 0
if (m1:=matches(name, pattern['right'], tree))[-1] and (m2:=matches(name, pattern['left'], m1[0]))[-1]:
return m2[0], {'name':name, 'left':m1[1], 'right':m2[1]}, 1
return tree, None, 0
def reduce(tree):
yield (tree[:-1], tree[-1], 0)
for a, b in grammar:
if (m:=matches(a, b, tree))[-1]:
yield m
def get_asts(stream, queue=[]):
if queue:
if not stream and len(queue)==1:
yield queue
for a, b, c in reduce(queue):
if c:
yield from get_asts(stream, a [b])
if stream:
yield from get_asts(stream[1:], queue [stream[0]])
t = [{'name':i} for i in src.split()]
import json
for i in get_asts(t):
print(json.dumps(i, indent=4))
[
{
"name": "E",
"left": {
"name": "E",
"value": {
"name": "id"
}
},
"right": {
"name": "E",
"value": {
"name": "E",
"left": {
"name": "E",
"value": {
"name": "id"
}
},
"right": {
"name": "E",
"value": {
"name": "id"
}
}
}
}
}
]
[
{
"name": "E",
"left": {
"name": "E",
"value": {
"name": "E",
"left": {
"name": "E",
"value": {
"name": "id"
}
},
"right": {
"name": "E",
"value": {
"name": "id"
}
}
}
},
"right": {
"name": "E",
"value": {
"name": "id"
}
}
}
]
CodePudding user response:
This is not a recommendation, and I'm sure there are other Python parser generator capable of producing Earley parsers (or variants thereof).
But it is certainly possible to use Lark (link from the OP) to produce a parse forest. Select an "earley" parser and set the ambiguity option to "forest" (or "explicit" if there isn't too much ambiguity).