Is this proceeding correct?
My intention was to add a dropout layer after concatenation, but to do so i needed to adjust the concat layer's output to the appropriate 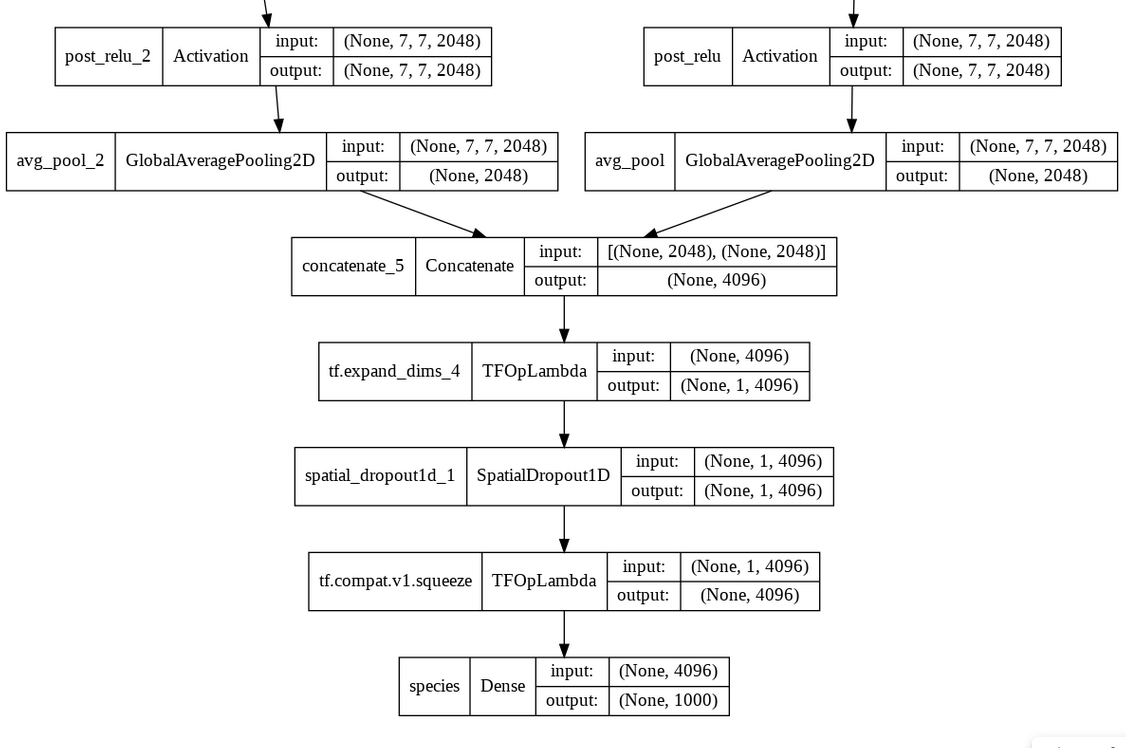
CodePudding user response:
Instead of explicitly adding a new dimension, in tensorflow 2.7.0 you could just use keepdims=True as an argument of the GlobalAveragePooling2D layer.
Example:
def TestModel():
# specify the input shape
in_1 = tf.keras.layers.Input(shape = (256,256,3))
in_2 = tf.keras.layers.Input(shape = (256,256,3))
x1 = tf.keras.layers.Conv2D(64, (3,3))(in_1)
x1 = tf.keras.layers.LeakyReLU()(x1)
x1 = tf.keras.layers.GlobalAveragePooling2D(keepdims = True)(x1)
x2 = tf.keras.layers.Conv2D(64, (3,3))(in_2)
x2 = tf.keras.layers.LeakyReLU()(x2)
x2 = tf.keras.layers.GlobalAveragePooling2D(keepdims = True)(x2)
x = tf.keras.layers.concatenate([x1,x2])
x = tf.keras.layers.SpatialDropout2D(0.2)(x)
x = tf.keras.layers.Dense(1000)(x)
# create the model
model = tf.keras.Model(inputs=(in_1,in_2), outputs=x)
return model
#Testcode
model = TestModel()
model.summary()
tf.keras.utils.plot_model(model, show_shapes=True, expand_nested=False, show_dtype=True, to_file="model.png")
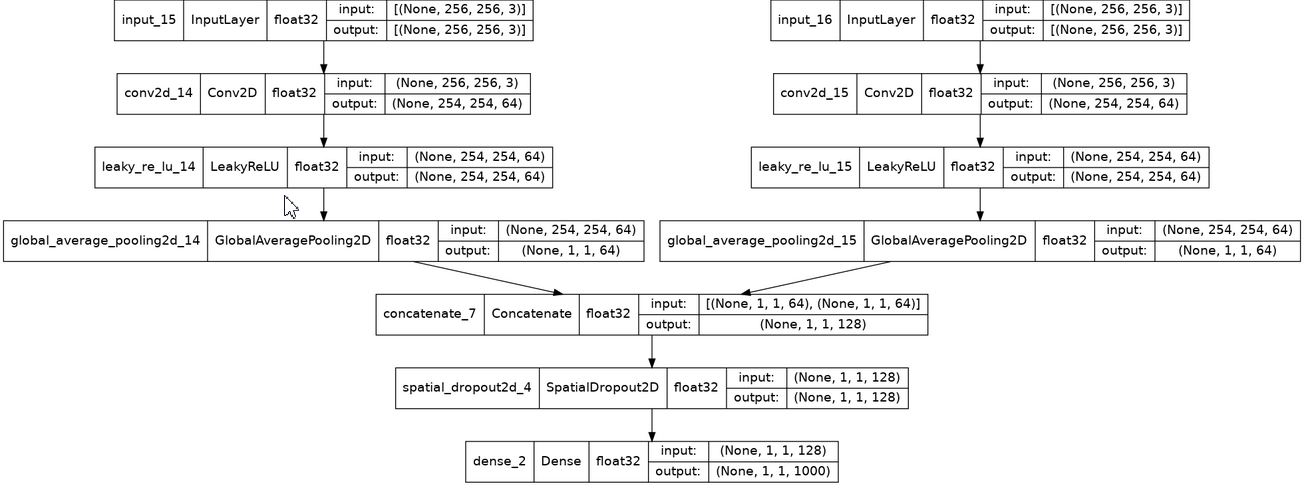
If you require to squeeze it in the end, you could still do it.
CodePudding user response:
If you plan to use the SpatialDropout1D layer, it has to receive a 3D tensor (batch_size, time_steps, features), so adding an additional dimension to your tensor before feeding it to the dropout layer is one option that is perfectly legitimate.
Note, though, that in your case you could use both SpatialDropout1D or Dropout:
import tensorflow as tf
samples = 2
timesteps = 1
features = 5
x = tf.random.normal((samples, timesteps, features))
s = tf.keras.layers.SpatialDropout1D(0.5)
d = tf.keras.layers.Dropout(0.5)
print(s(x, training=True))
print(d(x, training=True))
tf.Tensor(
[[[-0.5976591 1.481788 0. 0. 0. ]]
[[ 0. -4.6607018 -0. 0.7036132 0. ]]], shape=(2, 1, 5), dtype=float32)
tf.Tensor(
[[[-0.5976591 1.481788 0.5662646 2.8400114 0.9111476]]
[[ 0. -0. -0. 0.7036132 0. ]]], shape=(2, 1, 5), dtype=float32)
I think that SpatialDropout1D layers are most suitable after CNN layers.