I want to get tail rows with a condition
For example: I want all negative tail rows in a column 'A', while the input pandas data frame with 'A' column looks like:
test = pd.DataFrame({'A':[-8, -9, -10, 1, 2, 3, 0, -1,-2,-3]})
after the 'method' I expect to get new data frame like:
A
0 -1
1 -2
2 -3
note that, it is not certain of how many 'negative' numbers are in the tail. So, I can not run test.tail(3)
It looks like the pandas provided 'tail()' function can only run with a given number.
But my input data frame might be too large that I dont want run a simple loop to check one by one
Is there any better way to do that?
CodePudding user response:
What's the tail for? It seems like you just need the negative numbers
test.query("A < 0")
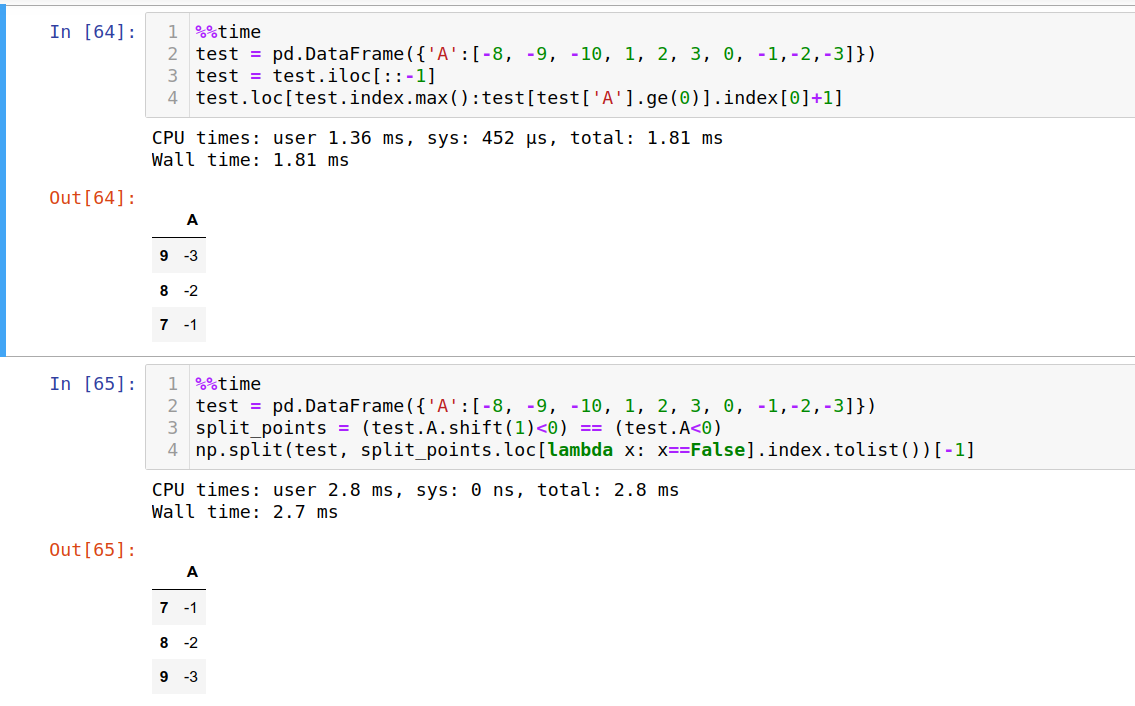
Update: Find where sign changes, split the array and choose last one
split_points = (test.A.shift(1)<0) == (test.A<0)
np.split(test, split_points.loc[lambda x: x==False].index.tolist())[-1]
Output:
A
7 -1
8 -2
9 -3
CodePudding user response:
Is this what you wanted?
test = pd.DataFrame({'A':[-8, -9, -10, 1, 2, 3, 0, -1,-2,-3]})
test = test.iloc[::-1]
test.loc[test.index.max():test[test['A'].ge(0)].index[0] 1]
Output:
A
9 -3
8 -2
7 -1
edit, if you want to get it back into the original order:
test.loc[test.index.max():test[test['A'].ge(0)].index[0] 1].iloc[::-1]
A
7 -1
8 -2
9 -3
Optional also .reset_index(drop=True) if you need a index starting at 0.
CodePudding user response:
Just share a picture of performance comparing above two given answers
Thansk Patry and Macro
CodePudding user response:
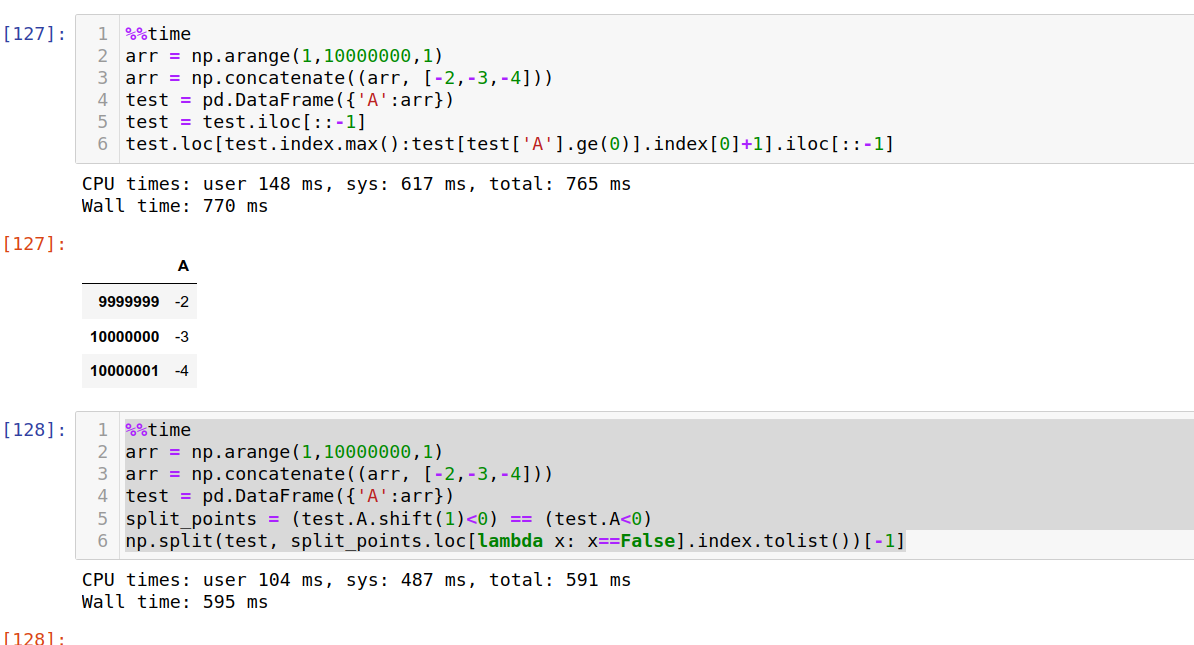
I improved my above test, and did another round test, as I feel the old 'testing sample' size was too small,and afaid the %%time measurement might not accurate.
My new test uses a very big head numbers with size of 10000000 and tail with 3 negative numbers
so the new test can prove how the whole data frame size impact the over all performance.
code is like bellow:
%%time
arr = np.arange(1,10000000,1)
arr = np.concatenate((arr, [-2,-3,-4]))
test = pd.DataFrame({'A':arr})
test = test.iloc[::-1]
test.loc[test.index.max():test[test['A'].ge(0)].index[0] 1].iloc[::-1]
%%time
arr = np.arange(1,10000000,1)
arr = np.concatenate((arr, [-2,-3,-4]))
test = pd.DataFrame({'A':arr})
split_points = (test.A.shift(1)<0) == (test.A<0)
np.split(test, split_points.loc[lambda x: x==False].index.tolist())[-1]
due to system impacts, I tested 10 times, the above 2 methods are very much performs the similar. In about 50% cases Patryk's code even performs faster
Check out this image bellow