I need to set all the values that are greater than 30 in a dataset as missing values. My dataset is huge, but here is the format of my df:
| date | A | B |
|---|---|---|
| 01/01/2021 | 20 | 5 |
| 01/02/2021 | 15 | 20 |
| 01/01/2022 | 17 | 30 |
| 01/01/2023 | 30 | 40 |
expected result:
| date | A | B |
|---|---|---|
| 01/01/2021 | 20 | 5 |
| 01/02/2021 | 15 | 20 |
| 01/01/2022 | 17 | NAN |
| 01/01/2023 | NAN | NAN |
Would be also nice to count how many of the values are bigger than 30, in this case, 3.
As asked below, I have tried the code:
df= df.apply(lambda x: [y if y <= 30 else NAN for y in x])
Output:
TypeError: '>=' not supported between instances of 'str' and 'int'
CodePudding user response:
you should try:
df[df[["A", "B"]].astype(int)>=30] = pd.NA
CodePudding user response:
You can replace the values in individual columns greater than or equal to 30 with 'NAN', and then count them.
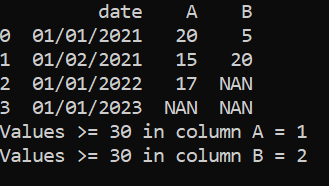
df = pd.DataFrame(d)
df.A[df.A >= 30] = 'NAN'
df.B[df.B >= 30] = 'NAN'
print(df)
print('Values >= 30 in column A =', df.A.value_counts()['NAN'])
print('Values >= 30 in column B =', df.B.value_counts()['NAN'])