I am working on a project where I am doing OCR on text on a label. My job is to deskew the image to make it readable with tesseract.

I have been using  , but not on images with background, like the presented image. There, it calculates a skew angle of 0.0 and does not rotate the image. (Expected result: 17°)
, but not on images with background, like the presented image. There, it calculates a skew angle of 0.0 and does not rotate the image. (Expected result: 17°)

I suspect this happens because there are black pixels in the background. Because of them the minAreaRect goes around the whole picture, thus leading to a skew angle of 0.
I tried doing a background removal, but couldn't find a method that works well enough so that only the label with the text is left
Another approach I tried was clustering the pixels through k-means-clustering. But even when choosing a good k manually, the cluster with the text still contains parts of the background.

Not to mention that I would still need another method that goes through all the clusters and uses some sort of heuristic to determine which cluster is text and which is background, which would cost a lot of runtime.
What is the best way to deskew an image that has background?
CodePudding user response:
You can try deep learning based natural scene text detection methods. With these methods you can get rotated bounding boxes for each text. Based on these get rotated bounding rectangle covering all boxes. Then use the 4 corners of that rectangle to correct the image.
RRPN_plusplus
Based on sample image 
EAST
Pyimagesearch has a tutorial with EAST scene text detector. Though not sure east will do good with extreme angles.
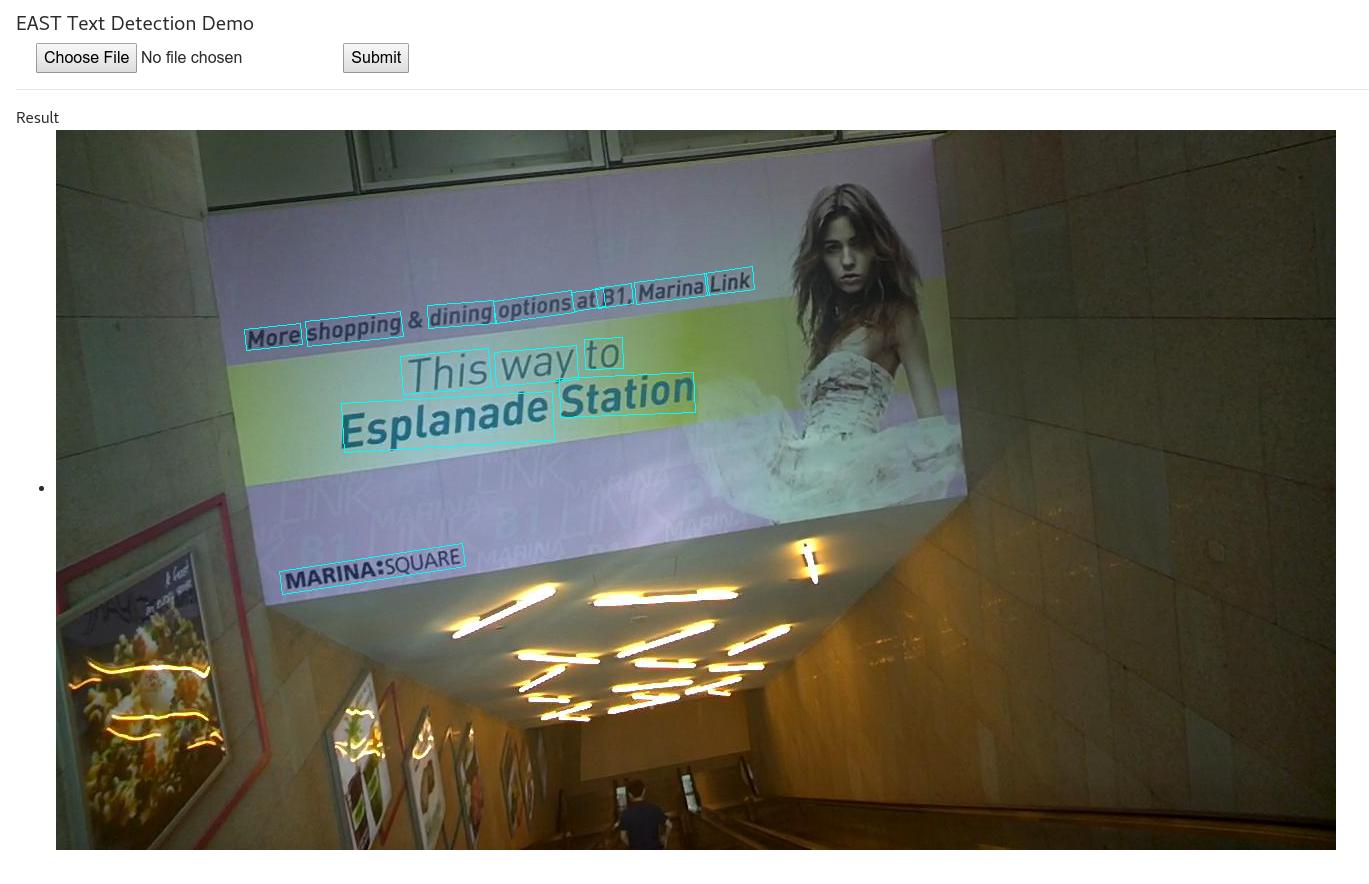
Image from, https://github.com/argman/EAST.
These should help you find recent better repos and methods,
- https://github.com/topics/scene-text-detection
- https://paperswithcode.com/task/scene-text-detection
- https://paperswithcode.com/task/curved-text-detection
CodePudding user response:
You can use easy-OCR which implements the methods mentioned in @B200011011 answer.
- Detect and mask the QR code, with pyzbar for example, to enhance the results.
- Use Easy-OCR.
the output without step 1(pyzbar) is:
DS PNBINSDA1 CNPNBINSDA1 O9NOM4S
import cv2
import easyocr
# TODO: change to suit your path
path = ""
img = cv2.imread(path "input.png")
reader = easyocr.Reader(['en'])
output = reader.readtext(img)
for i in range(len(output)):
print(output[i][-2])
- Note that this model still doesn't detect special characters like
$and it interpret it asS.