I'm supposed to code a function that Receives a labeled dataset and splits the datapoints according to label:
def get_clusters(X: np.ndarray, y: np.ndarray) -> List[np.ndarray]:
"""
Receives a labeled dataset and splits the datapoints according to label
Args:
X (np.ndarray): The dataset
y (np.ndarray): The label for each point in the dataset
Returns:
List[np.ndarray]: A list of arrays where the elements of each array
are datapoints belonging to the label at that index.
Example:
>>> get_clusters(
np.array([[0.8, 0.7], [0, 0.4], [0.3, 0.1]]),
np.array([0,1,0])
)
>>> [array([[0.8, 0.7],[0.3, 0.1]]),
array([[0. , 0.4]])]
"""
idx = np.unique(y,return_index = True)[1]
C = []
for i,label in enumerate(np.unique(y)):
if i != len(idx)-1:
C.append(X[idx[i]:idx[i 1]])
else:
C.append(X[idx[i]:])
return C
This is what I tried so far, but appearently it only works with a sorted input. I'm not allowed to use more then one for loop. Has anyone an idea how I can improve the function?
I hope I included all necessary information.
CodePudding user response:
Sorting seems like a lot of work. Another option is using np.where to get indices.
import numpy as np
def get_clusters(X: np.ndarray, y: np.ndarray) -> List[np.ndarray]:
return [X[np.where(y == label)[0], :] for label in np.unique(y)]
Gives the same result:
get_clusters(
np.array([[0.8, 0.7], [0, 0.4], [0.3, 0.1]]),
np.array([0,1,0])
)
[array([[0.8, 0.7],
[0.3, 0.1]]),
array([[0. , 0.4]])]
CodePudding user response:
You can split an array into a list of subarrays with 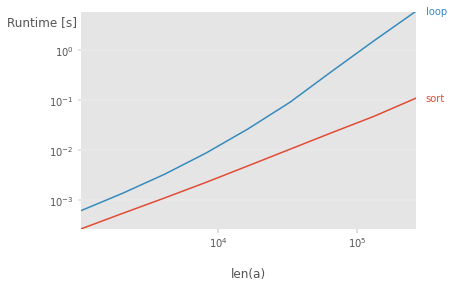
Results for decreasing unique labels (10000/10 to 10000/90, the x-axis label is incorrect) constant array size of 10000
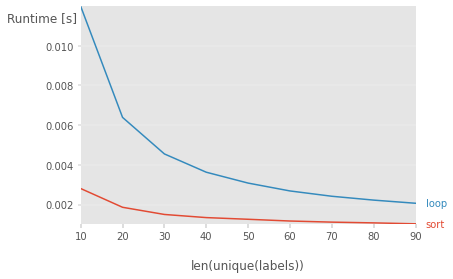
Code used for the benchmark
import numpy as np
from typing import List
import perfplot
def get_clusters_sort(X: np.ndarray, y: np.ndarray) -> List[np.ndarray]:
s = np.argsort(y)
return np.split(X[s], np.unique(y[s], return_index=True)[1][1:])
def get_clusters_loop(X: np.ndarray, y: np.ndarray) -> List[np.ndarray]:
return [X[np.where(y == label)[0]] for label in np.unique(y)]
perfplot.show(
setup = lambda n: (np.random.rand(n,2), np.random.randint(n//10, size=n)),
kernels = [
lambda x: get_clusters_sort(*x),
lambda x: get_clusters_loop(*x)
],
labels = ['sort','loop'],
n_range = [2**k for k in range(10,19)],
xlabel = 'len(a)',
equality_check=False
)
Code changes to estimate the influence of len(unique(labels))
perfplot.show(
setup = lambda n: (np.random.rand(10000,2), np.random.randint(10000//n, size=10000)),
kernels = [
lambda x: get_clusters_sort(*x),
lambda x: get_clusters_loop(*x)
],
labels = ['sort','loop'],
n_range = [k for k in range(10,100,10)],
xlabel = 'len(unique(labels))',
equality_check=False
)