I know there's a ton resources online for outlier removal, but I haven't yet managed to obtain what I exactly want, so posting here, I have an array (or DF) of 4 columns. Now I want to remove the rows from the DF based on a column's outlier values. The following is what I have tried, but they are not perfect.
def outliers2(data2, m = 4.5):
c=[]
data = data2[:,1] # Choosing the column
d = np.abs(data - np.median(data)) # deviation comoutation
mdev = np.median(d) # mean deviation
for i in range(len(data)):
if (abs(data[i] - mdev) < m * np.std(data)):
c.append(data2[i])
return c
x = pd.DataFrame(outliers2(np.array(b)))
column = ['t','orig_w','filt_w','smt_w']
x.columns = column
#Plot
plt.rcParams['figure.figsize'] = [10,8]
plt.plot(b.t,b.orig_w,'o',label='Original',alpha=0.8) # Original
plt.plot(x.t,x.orig_w,'.',c='r',label='Outlier removed',alpha=0.8) # After outlier removal
plt.legend()
the plot illustrates how the results looks, red points after the outlier treatment over the blue original points. I would really like to get rid of those vertical group of points around the x~0 mark. What to do ?
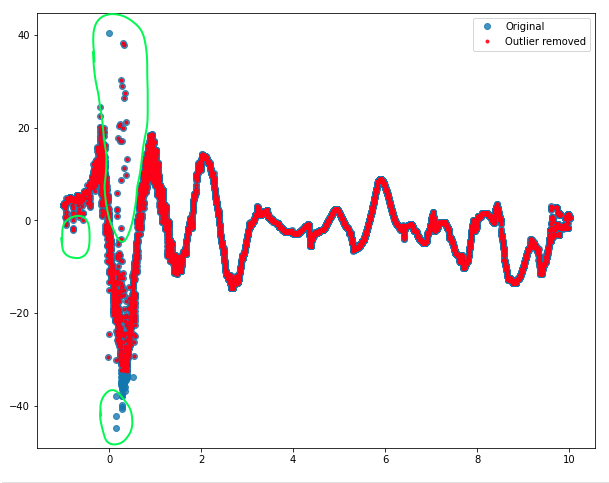
A link to the data file is provided here : 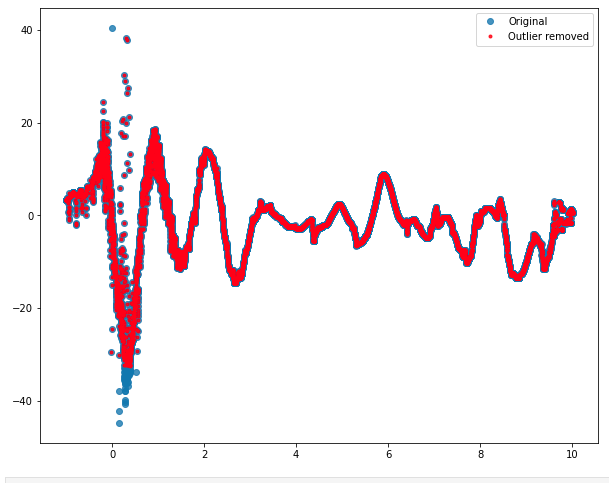 The green circles show typically the points i would like to get rid of
The green circles show typically the points i would like to get rid of
CodePudding user response:
You could use 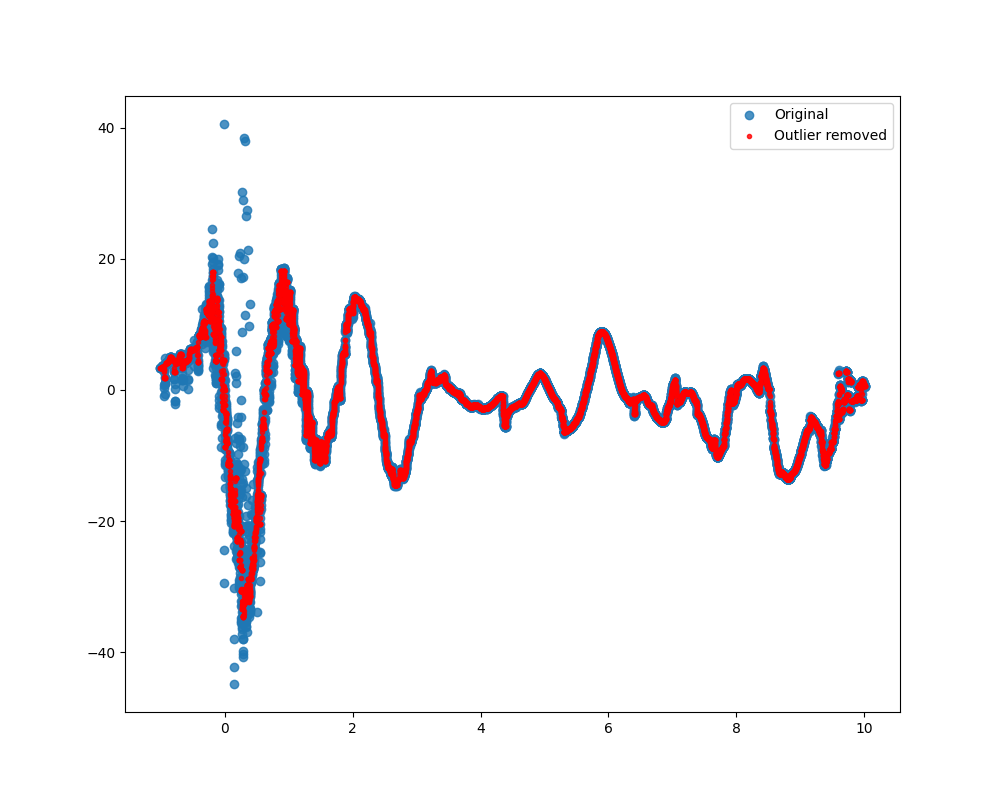
CodePudding user response:
Since your data looks sinusoidal, it probably makes sense to perform your outliers removal technique by using a sliding window. You can compute median and standard deviation in the direct neighborhood of the points you are testing and check if it's an outlier by checking if your point is within a specified number of the standard deviation from your median. This method exists under the name of Hampel filter (more details 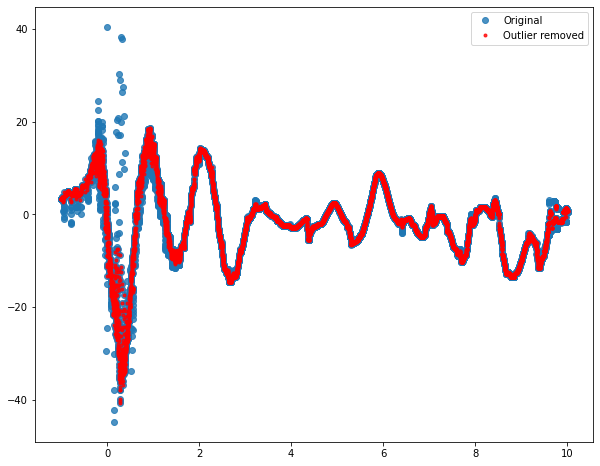
You can then fine tune win and m to get a result that works for you.