I have table like below:

I want to replace the null values for tier_1 and tier_2 with the value with highest frequency of tier_1 and tier_2 resp. group by name.
something like below:
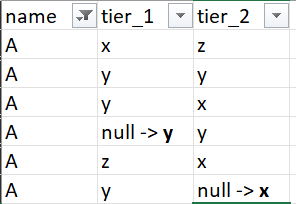
similarly had to find for other names B and C. I tried with the below query, and it gives correct count:
select tier_1,name,max(tr_cnt) from (
select name,tier_1, count(tier_1) as tr_cnt from `my_table` group by tier_1,name having count(tier_1) >=1
)group by name,tier_1
the above code does work to an extent but then when i add tier_2 also in the query: It says, Scalar subquery produced more than one element
Is there a way to achieve this and replace the nulls with the max occurring value from that col?
CodePudding user response:
Use COUNT() window function to get the number of each name and tier_x combination and FIRST_VALUE() window function to pick the tier_x that occurs the most:
WITH cte AS (
SELECT *,
COUNT(tier_1) OVER (PARTITION BY name, tier_1) counter1,
COUNT(tier_2) OVER (PARTITION BY name, tier_2) counter2
FROM my_table
)
SELECT name,
COALESCE(tier_1, FIRST_VALUE(tier_1) OVER (PARTITION BY name ORDER BY counter1 DESC)) tier_1,
COALESCE(tier_2, FIRST_VALUE(tier_2) OVER (PARTITION BY name ORDER BY counter2 DESC)) tier_2
FROM cte;
Note that in case of ties you will get an arbitrary value as the top tier_x.
If you want to break that tie you could use one more level of sorting in the ORDER BY clause of FIRST_VALUE() window function:
WITH cte AS (
SELECT *,
COUNT(tier_1) OVER (PARTITION BY name, tier_1) counter1,
COUNT(tier_2) OVER (PARTITION BY name, tier_2) counter2
FROM my_table
)
SELECT name,
COALESCE(tier_1, FIRST_VALUE(tier_1) OVER (PARTITION BY name ORDER BY counter1 DESC, tier_1)) tier_1,
COALESCE(tier_2, FIRST_VALUE(tier_2) OVER (PARTITION BY name ORDER BY counter2 DESC, tier_2)) tier_2
FROM cte;
See the 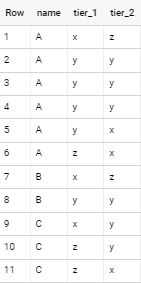
Note use of Approximate aggregate function APPROX_TOP_SUM
Approximate aggregate functions are scalable in terms of memory usage and time, but produce approximate results instead of exact results. These functions typically require less memory than exact aggregation functions like COUNT(DISTINCT ...), but also introduce statistical uncertainty. This makes approximate aggregation appropriate for large data streams for which linear memory usage is impractical, as well as for data that is already approximate.