I am trying to improve my model training performance following the 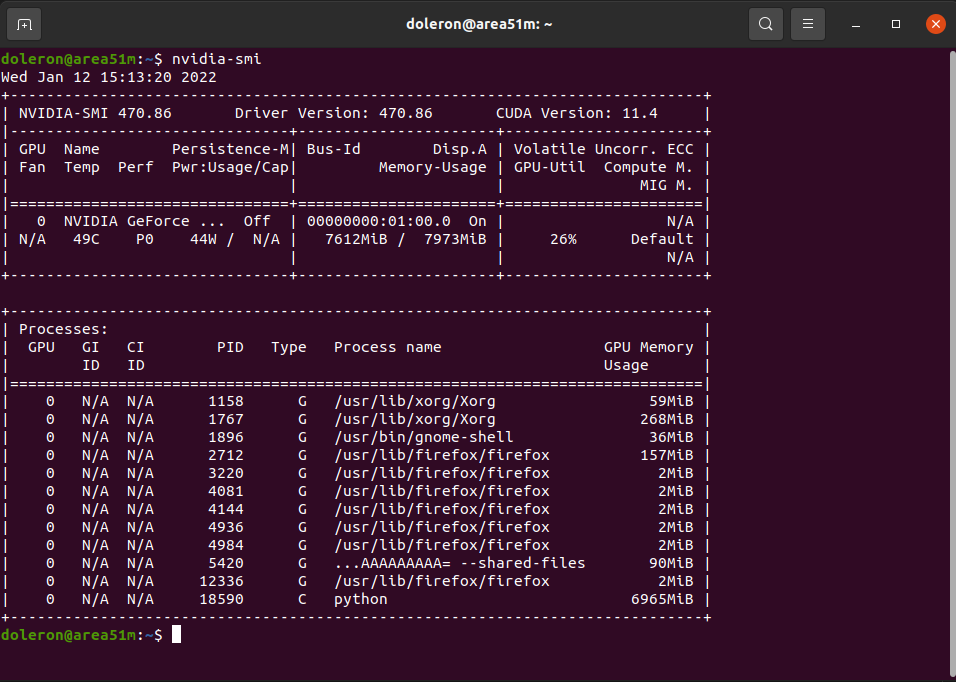
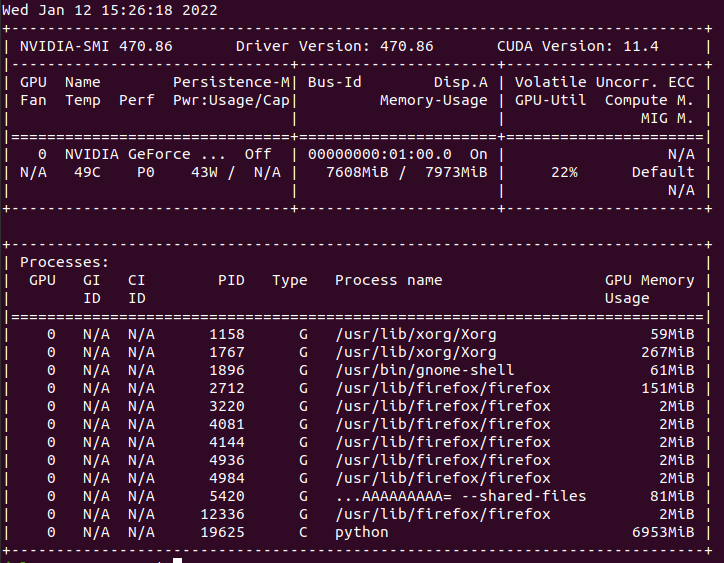
GPU usage during training WITHOUT cache:
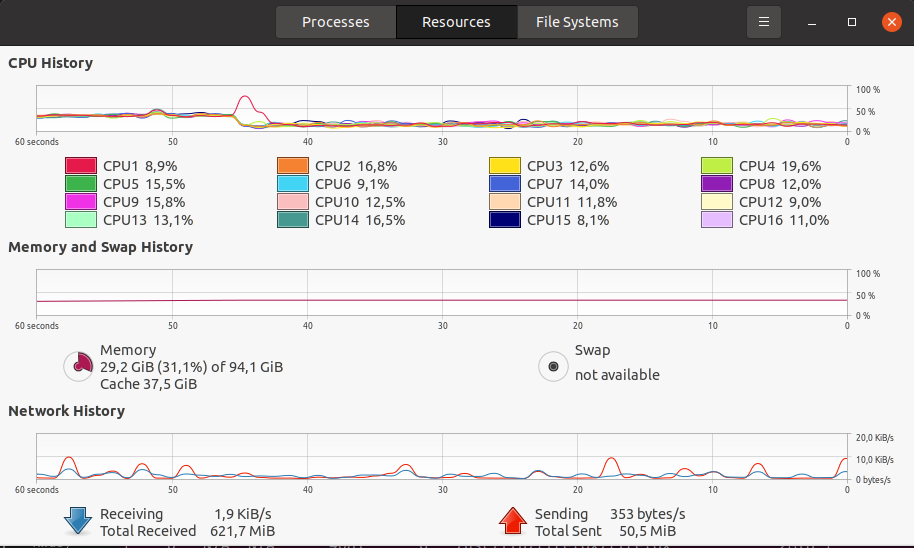
System Stats (Memory, CPU etc) during training using cache:
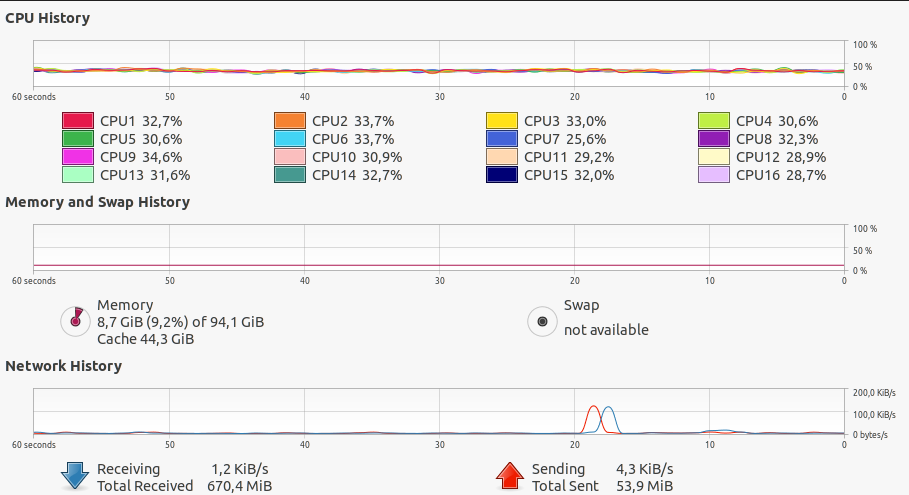
System Stats (Memory, CPU etc) during training WITHOUT cache:
CodePudding user response:
Just a small observation using Google Colab. According to the docs:
Note: For the cache to be finalized, the input dataset must be iterated through in its entirety. Otherwise, subsequent iterations will not use cached data.
And
Note: cache will produce exactly the same elements during each iteration through the dataset. If you wish to randomize the iteration order, make sure to call shuffle after calling cache.
I did notice a few differences when using caching and iterating over the dataset beforehand. Here is an example.
Prepare data:
import random
import struct
import tensorflow as tf
import numpy as np
RAW_N = 2 20*20 1
bytess = random.sample(range(1, 5000), RAW_N*4)
with open('mydata.bin', 'wb') as f:
f.write(struct.pack('1612i', *bytess))
def decode_and_prepare(register):
register = tf.io.decode_raw(register, out_type=tf.float32)
inputs = register[2:402]
label = tf.random.uniform(()) register[402:]
return inputs, label
raw_dataset = tf.data.FixedLengthRecordDataset(filenames=['/content/mydata.bin']*7000, record_bytes=RAW_N*4)
raw_dataset = raw_dataset.map(decode_and_prepare)
Train model without caching and iterating beforehand:
total_data_entries = len(list(raw_dataset.map(lambda x, y: (x, y))))
train_ds = raw_dataset.shuffle(buffer_size=total_data_entries).batch(32).prefetch(tf.data.AUTOTUNE)
inputs = tf.keras.layers.Input((400,))
x = tf.keras.layers.Dense(200, activation='relu', kernel_initializer='normal')(inputs)
x = tf.keras.layers.Dense(100, activation='relu', kernel_initializer='normal')(x)
outputs = tf.keras.layers.Dense(1, kernel_initializer='normal')(x)
model = tf.keras.Model(inputs, outputs)
model.compile(optimizer='adam', loss='mse')
model.fit(train_ds, epochs=5)
Epoch 1/5
875/875 [==============================] - 4s 3ms/step - loss: 0.1425
Epoch 2/5
875/875 [==============================] - 4s 3ms/step - loss: 0.0841
Epoch 3/5
875/875 [==============================] - 4s 3ms/step - loss: 0.0840
Epoch 4/5
875/875 [==============================] - 4s 3ms/step - loss: 0.0840
Epoch 5/5
875/875 [==============================] - 4s 3ms/step - loss: 0.0840
<keras.callbacks.History at 0x7fc41be037d0>
Training model with caching but no iterating:
total_data_entries = len(list(raw_dataset.map(lambda x, y: (x, y))))
train_ds = raw_dataset.shuffle(buffer_size=total_data_entries).cache().batch(32).prefetch(tf.data.AUTOTUNE)
inputs = tf.keras.layers.Input((400,))
x = tf.keras.layers.Dense(200, activation='relu', kernel_initializer='normal')(inputs)
x = tf.keras.layers.Dense(100, activation='relu', kernel_initializer='normal')(x)
outputs = tf.keras.layers.Dense(1, kernel_initializer='normal')(x)
model = tf.keras.Model(inputs, outputs)
model.compile(optimizer='adam', loss='mse')
model.fit(train_ds, epochs=5)
Epoch 1/5
875/875 [==============================] - 4s 2ms/step - loss: 0.1428
Epoch 2/5
875/875 [==============================] - 2s 2ms/step - loss: 0.0841
Epoch 3/5
875/875 [==============================] - 2s 2ms/step - loss: 0.0840
Epoch 4/5
875/875 [==============================] - 2s 2ms/step - loss: 0.0840
Epoch 5/5
875/875 [==============================] - 2s 3ms/step - loss: 0.0840
<keras.callbacks.History at 0x7fc41fa87810>
Training model with caching and iterating:
total_data_entries = len(list(raw_dataset.map(lambda x, y: (x, y))))
train_ds = raw_dataset.shuffle(buffer_size=total_data_entries).cache().batch(32).prefetch(tf.data.AUTOTUNE)
_ = list(train_ds.as_numpy_iterator()) # iterate dataset beforehand
inputs = tf.keras.layers.Input((400,))
x = tf.keras.layers.Dense(200, activation='relu', kernel_initializer='normal')(inputs)
x = tf.keras.layers.Dense(100, activation='relu', kernel_initializer='normal')(x)
outputs = tf.keras.layers.Dense(1, kernel_initializer='normal')(x)
model = tf.keras.Model(inputs, outputs)
model.compile(optimizer='adam', loss='mse')
model.fit(train_ds, epochs=5)
Epoch 1/5
875/875 [==============================] - 3s 3ms/step - loss: 0.1427
Epoch 2/5
875/875 [==============================] - 2s 2ms/step - loss: 0.0841
Epoch 3/5
875/875 [==============================] - 2s 2ms/step - loss: 0.0840
Epoch 4/5
875/875 [==============================] - 2s 2ms/step - loss: 0.0840
Epoch 5/5
875/875 [==============================] - 2s 2ms/step - loss: 0.0840
<keras.callbacks.History at 0x7fc41ac9c850>
Conclusion: The caching and the prior iteration of the dataset seem to have an effect on training, but in this example only 7000 files were used.