As the title suggests, I am trying to scrape a table using both Beautifulsoup and Selenium. I'm aware I most likely do not need both libraries, however I wanted to try if using Selenium's xpathselectors would help, which unfortunately they did not.
The website can be found here:
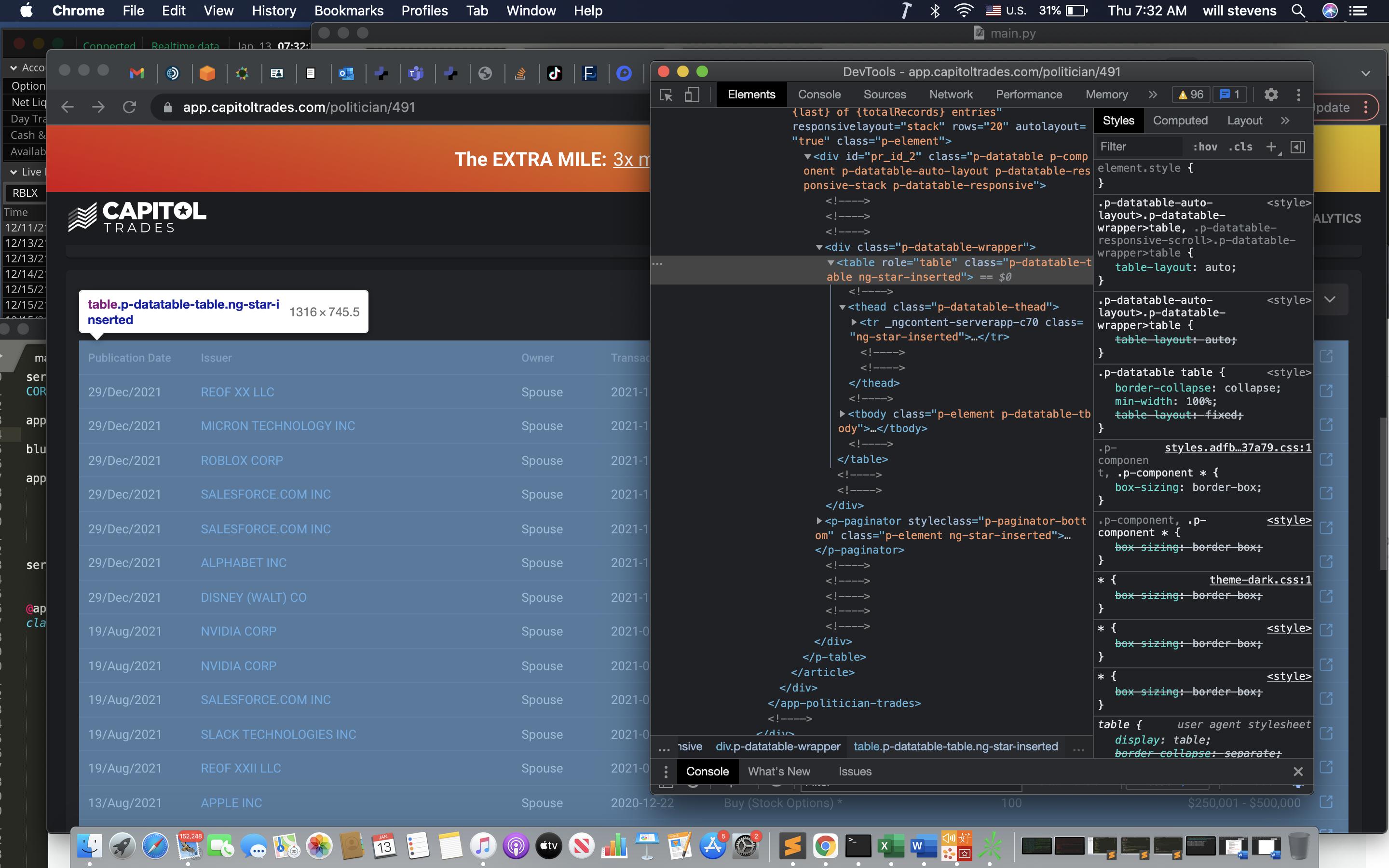
Once I can grab the table, I will collect the td data inside the table rows.
So for example, I would want '29/Dec/2021'under 'Publication Date'. Unfortunately, I haven't been able to get this far because I can't grab the table.
Here is my code:
from bs4 import BeautifulSoup
import requests
from selenium import webdriver
url = 'https://app.capitoltrades.com/politician/491'
resp = requests.get(url)
#soup = BeautifulSoup(resp.text, "html5lib")
soup = BeautifulSoup(resp.text, 'lxml')
table = soup.find("table", {"class": "p-datatable-table ng-star-
inserted"}).findAll('tr')
print(table)
This yields the error message "AttributeError: 'NoneType' object has no attribute 'findAll'
Using 'soup.findAll' also does not work.
If I try the xpathselector route using Selenium ...
DRIVER_PATH = '/Users/myname/Downloads/capitol-trades/chromedriver'
driver = webdriver.Chrome(executable_path=DRIVER_PATH)
driver.implicitly_wait(1000)
driver.get('https://app.capitoltrades.com/politician/491')
table = driver.find_element_by_xpath("//*[@id='pr_id_2']/div/table").text
print(table)
Chrome continues to open up and nothing gets printed inside my Jupyter notebook (probably because there is no text directly inside the table element[?])
I'd prefer to be able to grab the table element using Beautifulsoup, but all answers are welcomed. I appreciate any help you can provide me with.
CodePudding user response:
That site has a backend api that can be hit very easily:
import requests
import pandas as pd
url = 'https://api.capitoltrades.com/senators/trades/491/false?pageSize=20&pageNumber=1'
resp = requests.get(url).json()
df = pd.DataFrame(resp)
df.to_csv('naughty_nancy_trades.csv',index=False)
print('Saved to naughty_nancy_trades.csv ')
to see where all the data comes from open your browser's Developer Tools - Network - fetch/XHR and reload the page you'll see them fire. I've scraped one of those network calls, there are others for all the data on that page
CodePudding user response:
As per your Selenium code: you are missing a wait.
This
driver.find_element_by_xpath("//*[@id='pr_id_2']/div/table")
command returns you the web element when it is just created i.e already existing, but still not fully rendered.
This should work better:
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
DRIVER_PATH = '/Users/myname/Downloads/capitol-trades/chromedriver'
driver = webdriver.Chrome(executable_path=DRIVER_PATH)
wait = WebDriverWait(driver, 20)
driver.get('https://app.capitoltrades.com/politician/491')
table = wait.until(EC.visibility_of_element_located((By.XPATH, "//*[@id='pr_id_2']//tr[@class='p-selectable-row ng-star-inserted']"))).text
print(table)
As per you BS4 code, looks like you are using a wrong locator.
This:
table = soup.find("table", {"class": "p-datatable-table ng-star-inserted"})
looks to be better (you have extra spaces in your class name).
The line above returns 5 elements.
So this supposed to work:
table = soup.find("table", {"class": "p-datatable-table ng-star-inserted"}).findAll('tr')