I'm very new to BigQuery and not terribly familiar with SQL. I have a table of data that looks like this, where MyDate is a Timestamp object:
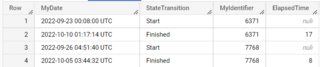
| Row | MyDate | StateTransition | MyIdentifier |
|---|---|---|---|
| 1 | 2022-09-23 00:08:00 UTC | Start | 6371 |
| 2 | 2022-10-10 01:17:14 UTC | Finished | 6371 |
| 3 | 2022-09-26 04:51:40 UTC | Start | 7768 |
| 4 | 2022-10-05 03:44:32 UTC | Finished | 7768 |
etc.
My query looks something like
SELECT *
FROM <my-data-source>
WHERE (StateTransition="Start" OR StateTransition="Finished")
ORDER BY MyIdentifier, MyDate
What I'm trying to do is calculate the elapsed time (in days) between the Start and Finished timestamps associated with each MyIdentifier, and to have that displayed in another column. It could look like:
| Row | MyDate | StateTransition | MyIdentifier | ElapsedTime |
|---|---|---|---|---|
| 1 | 2022-09-23 00:08:00 UTC | Start | 6371 | |
| 2 | 2022-10-10 01:17:14 UTC | Finished | 6371 | 0.33 |
| 3 | 2022-09-26 04:51:40 UTC | Start | 7768 | |
| 4 | 2022-10-05 03:44:32 UTC | Finished | 7768 | 0.04 |
Alternatively, it could even be flattened a little to something like:
| Row | StartTransition | FinishedTransition | MyIdentifier | ElapsedTime |
|---|---|---|---|---|
| 1 | 2022-09-23 00:08:00 UTC | 2022-10-10 01:17:14 UTC | 6371 | 0.33 |
| 2 | 2022-09-26 04:51:40 UTC | 2022-10-05 03:44:32 UTC | 7768 | 0.04 |
I've tried looking through the BigQuery docs and Stack Overflow but haven't found anything that addresses this use case of selecting items from multiple rows with a common identifier and then performing an operation on them. It seems like subtracting the two timestamps would be done with the 
But for the intermediate result, we need a window function.
SELECT *,
IF(
StateTransition = 'Finished',
TIMESTAMP_DIFF(MyDate, FIRST_VALUE(IF(StateTransition = 'Start', MyDate, NULL) IGNORE NULLS) OVER w, DAY),
NULL
) AS ElapsedTime
FROM sample_table
WINDOW w AS (PARTITION BY MyIdentifier ORDER BY MyDate);
and if you want flattend result from the above result (using a window function), the query will looks like below which shows same result as the first query using an aggregation.
SELECT MyIdentifier,
FIRST_VALUE(IF(StateTransition = 'Start', MyDate, NULL) IGNORE NULLS) OVER w AS StartTransition,
MyDate AS FinishedTransition,
IF(
StateTransition = 'Finished',
TIMESTAMP_DIFF(MyDate, FIRST_VALUE(IF(StateTransition = 'Start', MyDate, NULL) IGNORE NULLS) OVER w, DAY),
NULL
) AS ElapsedTime
FROM sample_table
QUALIFY StateTransition = 'Finished'
WINDOW w AS (PARTITION BY MyIdentifier ORDER BY MyDate);
CodePudding user response:
I think that for each MyIdentifier you should have only one start and one finish, so you can simply split and join:
;WITH
ts AS ( SELECT * FROM <my-data-source> WHERE StateTransition = 'Start'),
tf AS ( SELECT * FROM <my-data-source> WHERE StateTransition = 'Finished')
SELECT
ts.MyIdentifier,
ts.MyDate StartTransition,
tf.MyDate FinishedTransition,
TIMESTAMP_DIFF(ts.MyDate, tf.MyDate, DAY) ElapsedTime
FROM ts
LEFT JOIN tf on ts.MyIdentifier = tf.MyIdentifier