I have a string pdf_text(below)
pdf_text = """ Account History Report
IMAGE All Notes
Date Created:18/04/2022
Number of Pages: 4
Client Code - 110203 Client Name - AWS PTE. LTD.
Our Ref :2118881115 Name: Sky Blue Ref 1 :12-34-56789-2021/2 Ref 2:F2021004444
Amount: $100.11 Total Paid:$0.00 Balance: $100.11 Date of A/C: 01/08/2021 Date Received: 10/12/2021
Last Paid: Amt Last Paid: A/C Status: CLOSED Collector : Sunny Jane
Date Notes
04/03/2022 Letter Dated 04 Mar 2022.
Our Ref :2112221119 Name: Green Field Ref 1 :98-76-54321-2021/1 Ref 2:F2021001111
Amount: $233.88 Total Paid:$0.00 Balance: $233.88 Date of A/C: 01/08/2021 Date Received: 10/12/2021
Last Paid: Amt Last Paid: A/C Status: CURRENT Collector : Sam Jason
Date Notes
11/03/2022 Email for payment
11/03/2022 Case Status
08/03/2022 to send a Letter
08/03/2022 845***Ringing, No reply
21/02/2022 Letter printed - LET: LETTER 2
18/02/2022 Letter sent - LET: LETTER 2
18/02/2022 845***Line busy
"""
I need to split the string on the line Our Ref :Value Name: Value Ref 1 :Value Ref 2:Value . Which is the start of every data entity below(in rectangles)
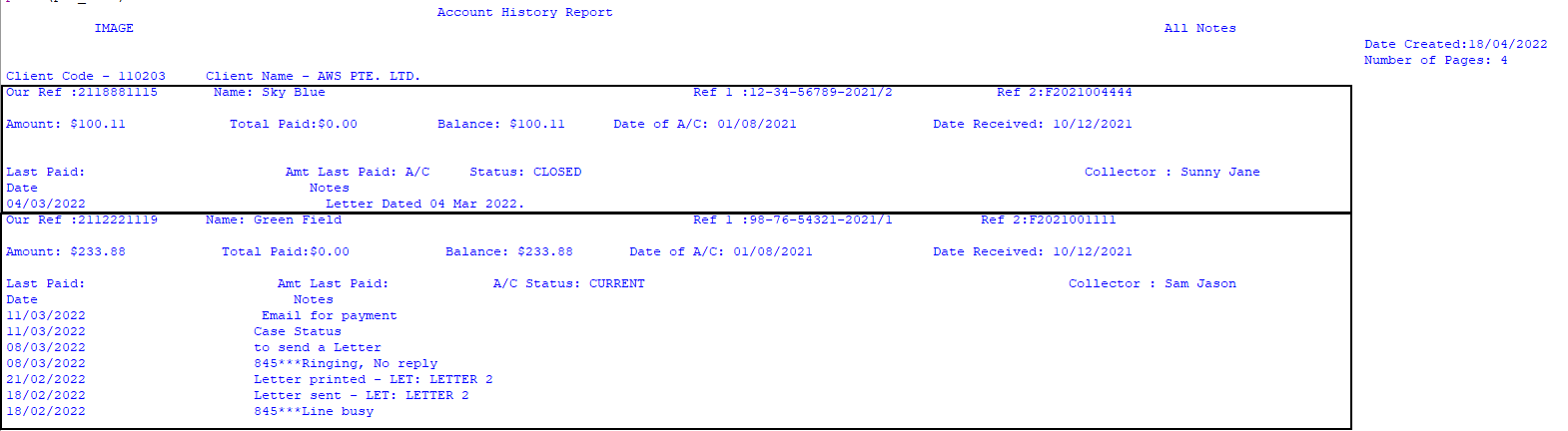
so that I get the squared entities(in above picture) in a different string.
I used the regex pattern
data_entity_sep_pattern = r'(Our Ref.*?Name.*?Ref 1.*?Ref 2.*?)'
But I don't see the separators being retained with the splitted lines.
split_on_data_entity = re.split(data_entity_sep_pattern, pdf_text.strip())
which gives me

which obviously was not expected. Expected was split_on_data_entity[1] and split_on_data_entity[2] be in one string and split_on_data_entity[3] and split_on_data_entity[4] to be in one string.
I was referring this answer https://stackoverflow.com/a/2136580/10216112 which explains parenthesis retains the string
CodePudding user response:
Expected was split_on_data_entity[1] and split_on_data_entity[2] be in one string
The parentheses retain the string, but in a separate chunk.
If you want to keep the string, but have it as part of the next chunk, use a look-ahead (?= )
Some other remarks:
You may also want to require that "Our ref" occurs as the first set of letters on a line. And when you are at it, you can remove such newline character, followed by optional white space.
There is no need to match
.*?at the very end of your patternAs the text comes from PDF, you maybe don't want to be too strict about the number of spaces between words. You could use
\s.
data_entity_sep_pattern = r'\n\s*(?=Our\s Ref.*?Name.*?Ref\s 1.*?Ref\s 2)'
split_on_data_entity = re.split(data_entity_sep_pattern, pdf_text)
for section in split_on_data_entity:
print(section)
print("--------------------------")