In a large program, I found a bug that numbers were coming out as NaN. I'm having trouble understanding the cause.
In the context of this larger problem, the import data often is detected as object because there are may be blanks "" or spaces " ". I want to change "" or " " (any number of spaces) to np.nan. I want this to work whether the input is a series with one element or many, and if the element is numeric or string.
However, when I try the regex that seems obvious, it changes a valid number to NaN. This is inside the debugger:
ipdb> temp_v1
value 1250.00
Name: standard, dtype: object
ipdb> temp_v1.replace(r"\s*", np.nan, regex=True)
value NaN
Name: standard, dtype: float64
ipdb> type(temp_v1)
<class 'pandas.core.series.Series'>
ipdb> temp_v1.dtype
dtype('O')
ipdb> temp_v1.str.replace(r"\s*", np.nan, regex=True)
*** TypeError: repl must be a string or callable
ipdb> temp_v1.astype(str).replace(r"\s*", np.nan, regex=True)
value NaN
Name: standard, dtype: float64
This is a simple mre for experimentation:
import pandas as pd
import numpy as np
x = pd.Series(['1250.00'])
x.replace(r"\s*", np.nan, regex=True)
When I run that, the output is NaN. Usually...
If I fiddle around in the terminal and try this over and over, it works correctly sometimes, but fails usually. This one succeeds, but I have no idea why.
In [19]: x = pd.Series(['123.44'])
In [20]: x.replace(r"\s*", "", regex=True)
Out[20]:
0 123.44
dtype: object
Do same a few lines later, fail:
In [29]: x = pd.Series(['123.44'])
In [30]: x.replace(r'\s*', np.nan, regex=True)
Out[30]:
0 NaN
dtype: float64
CodePudding user response:
It appears that python is stumbling on the regex. It can successfully identify the regex for checking for spaces, but sees everything has "no space". If I replace the np.nan with the string "7" then I can see that the replace statement is replacing all of the empty space between characters (instead of just checking for an empty cell).

If I replace your regex with an "or" statement checking for spaces or a completely empty cell, then I get what you are wanting to see.
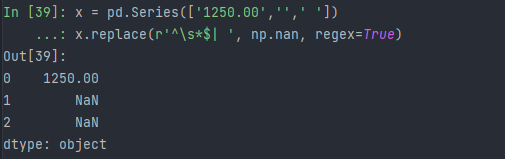
x = pd.Series(['1250.00','',' '])
x.replace(r'^\s*$| ', np.nan, regex=True)
CodePudding user response:
If you only want to handle blank and multi-space strings ("" or "\s ") you can use pd.to_numeric with errors="coerce"
import pandas as pd # version 1.1.5
x = pd.Series(["125.00", "", " ", "123.44"])
pd.to_numeric(x, errors="coerce")
Out
0 125.00
1 NaN
2 NaN
3 123.44
dtype: float64
Will also work if other string-values are present, though you may wish to inspect these further:
x = pd.Series(["125.00", "", " ", "123.44", "test"])
pd.to_numeric(x, errors="coerce")
Out
0 125.00
1 NaN
2 NaN
3 123.44
4 NaN
dtype: float64