I have two dataframes loaded from a .csv file. One contains numeric values, the other dates (month-year) for when these numeric values occured. The dates and values are basically mapped to each other. I would like to combine/merge these dataframes to have the dates as the column, and values as the rows. However, as you can see, the dates, though ordered from left to right, they don't all start on the same month.
import pandas as pd
df1 = pd.DataFrame(
[
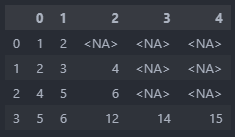
[1, 2, pd.NA, pd.NA, pd.NA],
[2, 3, 4, pd.NA, pd.NA],
[4, 5, 6, pd.NA, pd.NA],
[5, 6, 12, 14, 15]
]
)
df2 = pd.DataFrame(
[
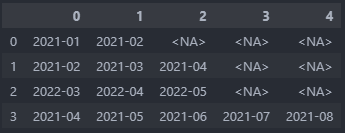
["2021-01", "2021-02", pd.NA, pd.NA, pd.NA],
["2021-02", "2021-03", "2021-04", pd.NA, pd.NA],
["2022-03", "2022-04", "2022-05", pd.NA, pd.NA],
["2021-04", "2021-05", "2021-06", "2021-07", "2021-08"]
]
)
df1
df2
Although I managed to create the combined dataframe, the dataframes, df1 and df2 contain ~300k rows, and the approach I thought of is rather slow. Is there a more efficient way of achieving the same result?
q = {z: {x: y for x, y in zip(df2.values[z], df1.values[z]) if not pd.isna(y)} for z in range(len(df2))}
df = pd.DataFrame.from_dict(q, orient='index')
idx = pd.to_datetime(df.columns, errors='coerce', format='%Y-%m').argsort()
df.iloc[:, idx]
df3 (result)

CodePudding user response:
You can stack, concat and pivot:
(pd.concat([df1.stack(), df2.stack()], axis=1)
.reset_index(level=0)
.pivot(index='level_0', columns=1, values=0)
.rename_axis(index=None, columns=None)
)
Alternative with unstack:
(pd.concat([df1.stack(), df2.stack()], axis=1)
.droplevel(1).set_index(1, append=True)
[0].unstack(1)
.rename_axis(columns=None)
)
output:
2021-01 2021-02 2021-03 2021-04 2021-05 2021-06 2021-07 2021-08 2022-03 2022-04 2022-05
0 1 2 NaN NaN NaN NaN NaN NaN NaN NaN NaN
1 NaN 2 3 4 NaN NaN NaN NaN NaN NaN NaN
2 NaN NaN NaN NaN NaN NaN NaN NaN 4 5 6
3 NaN NaN NaN 5 6 12 14 15 NaN NaN NaN
CodePudding user response:
Use concat with keys parameters, so possible after DataFrame.stack and convert MutiIndex to column use DataFrame.pivot:
df = (pd.concat([df1, df2], axis=1, keys=['a','b'])
.stack()
.reset_index()
.pivot('level_0','b','a'))
print (df)
b 2021-01 2021-02 2021-03 2021-04 2021-05 2021-06 2021-07 2021-08 \
level_0
0 1 2 NaN NaN NaN NaN NaN NaN
1 NaN 2 3 4 NaN NaN NaN NaN
2 NaN NaN NaN NaN NaN NaN NaN NaN
3 NaN NaN NaN 5 6 12 14 15
b 2022-03 2022-04 2022-05
level_0
0 NaN NaN NaN
1 NaN NaN NaN
2 4 5 6
3 NaN NaN NaN