I have the following dataframe. I need to groupby the ngram, and for each group, count how many unique documents are present in the DocID column.
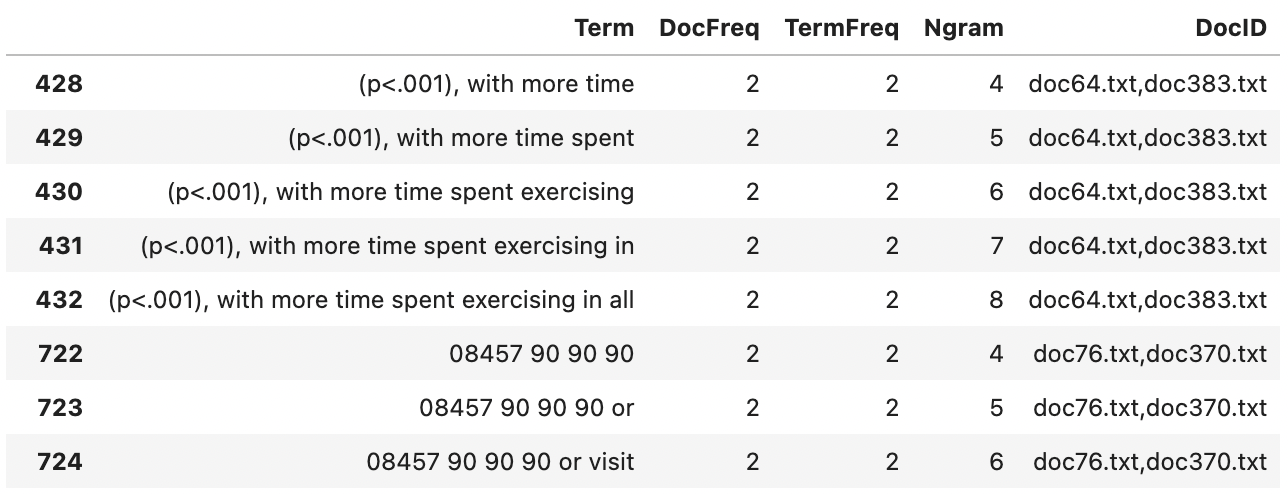
For example, from the above
4-gram group - 4 as number of unique documents (doc64,doc383,doc76,doc370)
5-gram - 4
6-gram - 4
7-gram - 2
8-gram - 2
I have an idea in bits. I can get the unique DocIDs as follows:
#Get all the docs of repeated summaries in one list as a list of lists.
rep = []
rep = temp['DocID'].str.split(",").tolist()
# Put all values in one list.
repSet = []
for i in range(len(rep)):
repSet.extend(rep[i])
# Remove all duplicates and store in a list.
repSet = list(set(repSet))
But I don't know how to merge this with groupby.
EDIT
I have added the output from the first answer provided. Thank you! But the total number of documents are only 461. So I believe the maximum value of the DocID can go up to only that much :( but for the trigram its above 461 :(
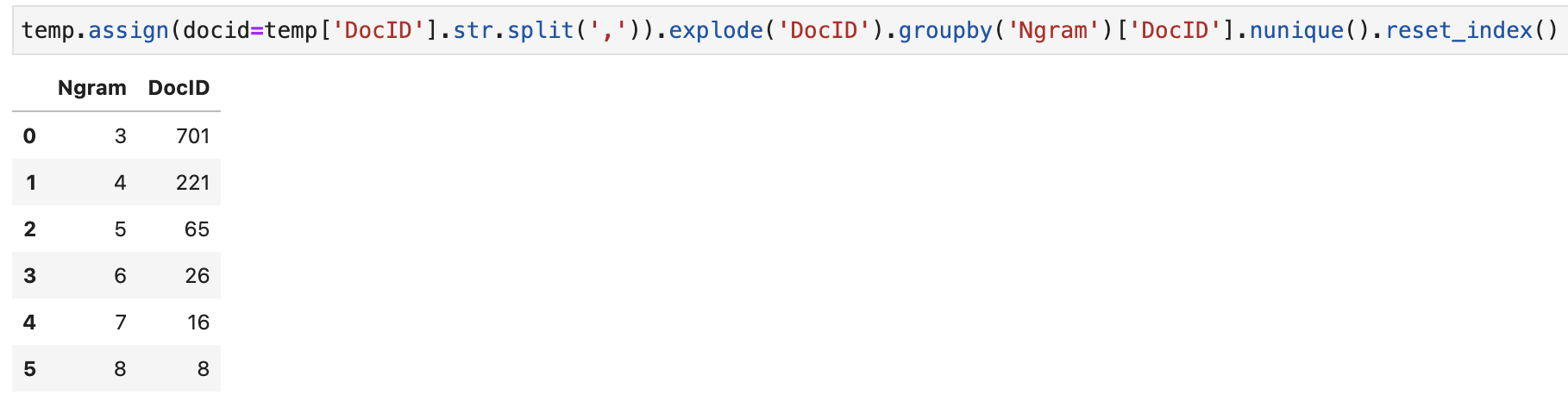
Help will be greatly appreciated. Thanks!
CodePudding user response:
Maybe something like this?
df.assign(docid=df['docid'].str.split(',')).explode('docid').groupby('ngram')['docid'].nunique().reset_index()