I have a dataset which I want to group by the age.
So, here is the first part of the dataset:
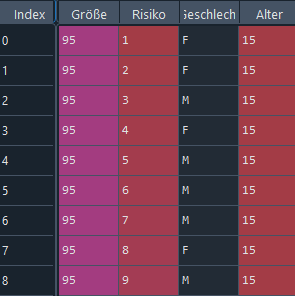
It is a simulation for a inventory data. Größe means the number of people with the age (Alter) 15. Risiko gives every person a number and Geschlecht is feminine or masculine.
I want to add a column "Group" and give every people, which have the age 15-19 one number, than with age 20-24 one number and so on. How can I do this?
CodePudding user response:
You can use map and lambda to create a new column like so :
def return_age_from_range(age):
# Max value in range is excluded, so remember to add 1 to the range you want
if age in range(15, 20):
return 1
elif age in range(20, 25):
return 2
# and so on...
df['group'] = df.alter.map(lambda x: return_age_from_range(x))
CodePudding user response:
Use numpy.select:
In [488]: import numpy as np
In [489]: conds = [df['Alter'].between(15,19), df['Alter'].between(20,24), df['Alter'].between(24,28)]
In [490]: choices = [1,2,3]
In [493]: df['Group'] = np.select(conds, choices)
In [494]: df
Out[494]:
Größe Risiko Geschlecht Alter Group
0 95 1 F 15 1
1 95 2 F 15 1
2 95 3 M 15 1
3 95 4 F 15 1
4 95 5 M 15 1
5 95 6 M 15 1
6 95 7 M 15 1
7 95 8 F 15 1
8 95 9 M 15 1