I want to move around description text column to newly created columns based on keywords in python.
For example, if keywords are 'Table', 'Fan', 'Chair'
Description(Given) Keyword Table Keyword Fan Keyword Chair
The table is long The table is long
The fan is nice The fan is nice
The fan is cheap The fan is cheap
The chair is brown The chair is brown
I tried to use both str.contains() and str.findall(), but it gives either T|F boolean or just the keyword (ex. 'chair')
df['Keyword Table'] = df['Description'].str.contains('Table')
AND
keywords=['Table']
df['Keyword Table'] = df['Description'].str.findall((keywords)).apply(set)
CodePudding user response:
Here is a simple way using a regex with named capturing groups:
df = pd.DataFrame({'Desc': ['The table is long', 'The fan is nice', 'The fan is cheap', 'The chair is brown']})
words = ['table', 'fan', 'chair']
regex = '|'.join(f'(?P<{w}>.*{w}.*)' for w in words)
df.join(df['Desc'].str.extract(regex, expand=False).add_prefix('keyword_'))
NB. The named capturing groups cannot have special characters or spaces.If this is the case let me know and it is possible to change the name of the capturing group. Output:
Desc keyword_table keyword_fan keyword_chair
0 The table is long The table is long NaN NaN
1 The fan is nice NaN The fan is nice NaN
2 The fan is cheap NaN The fan is cheap NaN
3 The chair is brown NaN NaN The chair is brown
other option get_dummies
df = pd.DataFrame({'Desc': ['The table is long', 'The fan is nice', 'The fan is cheap', 'The chair is brown']})
words = ['table', 'fan', 'chair']
regex = '(%s)' % '|'.join(words)
df.join(pd.get_dummies(df['Desc'].str.extract(regex, expand=False))
.mul(df['Desc'], axis=0)
.add_prefix('keyword_')
)
CodePudding user response:
Your boolean series can be used as index to slice your dataframe, like this:
df['Keyword Table'] = df[df['Description'].str.contains('Table', na = False)]['Description']
For a list of keywords, you can use apply:
keywords = ['Table', 'Fan', 'Chair']
df['Keywords'] = df[df['Description'].apply(lambda x: any(k in x for k in keywords))]['Description']
CodePudding user response:
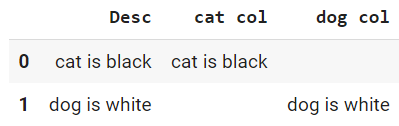
Does this piece of code help?
df = pd.DataFrame({'Desc':['cat is black','dog is white']})
kw = ['cat','dog']
for k in kw:
df[k ' col'] = df.Desc.map(lambda s: s if k in s else '' )
Output is