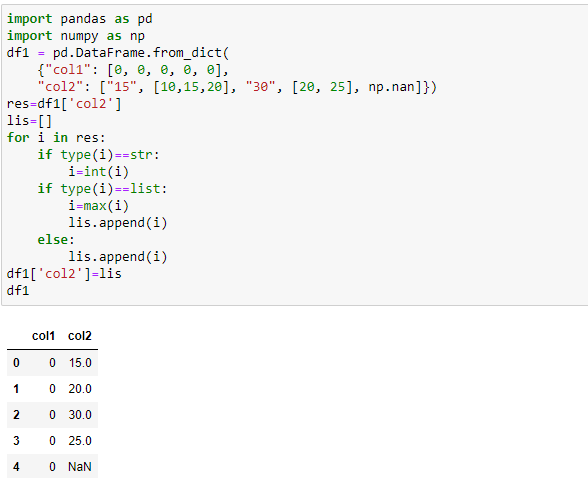
I have a dataframe
import pandas as pd
import numpy as np
df1 = pd.DataFrame.from_dict(
{"col1": [0, 0, 0, 0, 0],
"col2": ["15", [10,15,20], "30", [20, 25], np.nan]})
which looks like this
| col1 | col2 |
|---|---|
| 0 | "15" |
| 0 | [10,15,20] |
| 0 | "30" |
| 0 | [20,25] |
| 0 | NaN |
For col2, I need the highest value of each row, e.g. 15 for the first row and 20 for the second row, so that I end up with the following dataframe:
df2 = pd.DataFrame.from_dict(
{"col1": [0, 0, 0, 0, 0],
"col2": [15, 20, 30, 25, np.nan]})
which should look like this
| col1 | col2 |
|---|---|
| 0 | 15 |
| 0 | 20 |
| 0 | 30 |
| 0 | 25 |
| 0 | NaN |
I tried using a for-loop that checks which type col2 for each row has, and then converts str to int, applies max() to lists and leaves nan's as they are but did not succeed. This is how I did tried (although I suggest to just ignore my attempt):
col = df1["col2"]
coltypes = []
for i in col:
#get type of each row
coltype = type(i)
coltypes.append(coltype)
df1["coltypes"] = coltypes
#assign value to col3 based on type
df1["col3"] = np.where(df1["coltypes"] == str, df1["col1"].astype(int),
np.where(df1["coltypes"] == list, max(df1["coltypes"]), np.nan))
Giving the following error
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-10-b8eb266d5519> in <module>
9
10 df1["col3"] = np.where(df1["coltypes"] == str, df1["col1"].astype(int),
---> 11 np.where(df1["coltypes"] == list, max(df1["coltypes"]), np.nan))
TypeError: '>' not supported between instances of 'type' and 'type'
CodePudding user response:
Let us try explode then groupby with max
out = df1.col2.explode().groupby(level=0).max()
Out[208]:
0 15
1 20
2 30
3 25
4 NaN
Name: col2, dtype: object
CodePudding user response:
Another approach that might be easier to understand would be using apply() with a simple function that returns the max depending on the type.
import pandas as pd
import numpy as np
df1 = pd.DataFrame.from_dict(
{"col1": [0, 0, 0, 0, 0],
"col2": ["15", [10,15,20], "30", [20, 25], np.nan]})
def get_max(x):
if isinstance(x, list):
return max(x)
elif isinstance(x, str):
return int(x)
else:
return x
df1['max'] = df1['col2'].apply(get_max)
print(df1)
Output would be:
col1 col2 max
0 0 15 15.0
1 0 [10, 15, 20] 20.0
2 0 30 30.0
3 0 [20, 25] 25.0
4 0 NaN NaN
CodePudding user response:
@ratsrule23,
You will find the exact same question answered here