I have a dataframe of tank level, which can be quite noisy.
I have written an algorithm to (accurately & consistently!) detect peaks and troughs and I now need to remove data on one (filling) part of the cycle, between the grey points and orange points in the image below:
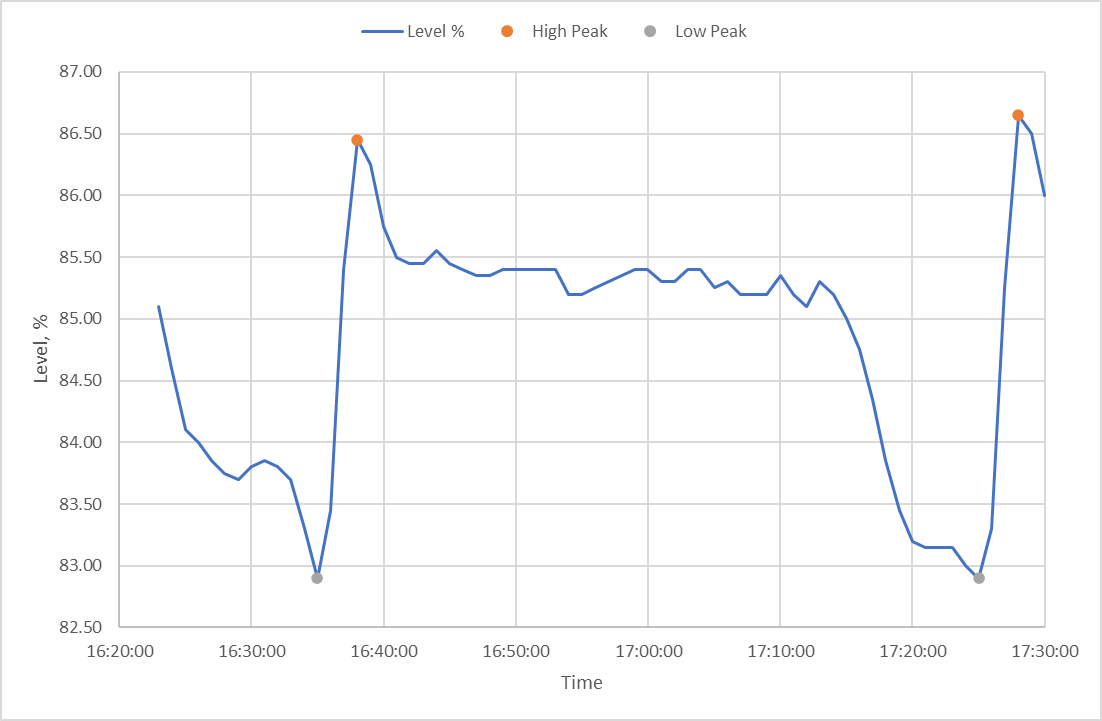
Thanks to @piterbarg and @richardec, I can recognize the next peak following a trough but now I am stuck on how to remove the data between the two (including the High Peak) (colored red below) to only perform further calculations when the level is dropping:
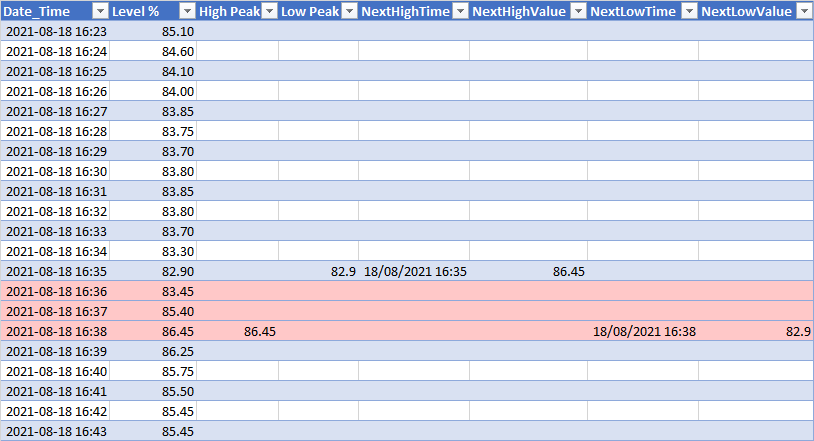
A csv copy of the dataframe is on GitHub. The full data set is > 2M rows, so row-wise calculations are out of the question!
I am completely stuck just now so any help is gratefully received!
CodePudding user response:
Solved, and much more simply than I was originally thinking:
##Add an empty 'NewCol'
df['NewCol'] = None
##Add the word 'High' where a High Peak is seen
df.loc[df['High Peak'].notna(), 'NewCol'] = 'High'
##Add the word 'Low' where a Low Peak is seen
df.loc[df['Low Peak'].notna(), 'NewCol'] = 'Low'
##Back fill the word 'High' & 'Low'
df['NewCol'].bfill(inplace=True)
##Remove rows with 'High'
df = df[df['NewCol'] != 'High']