I am doing some web scraping to export text info from an html and using a NER (Spacy) to identify information such as Assets Under Management, Addresses, and founding dates of companies. Once the information is extracted, I would like to place it in a dataframe.
I am working with the following script:
from bs4 import BeautifulSoup
import numpy as np
from time import sleep
from random import randint
from selenium import webdriver
import pandas as pd
import spacy
from spacy import displacy
import en_core_web_sm
import requests
import re
NER = spacy.load("en_core_web_sm")
url = "https://www.baincapital.com/"
driver = webdriver.Chrome("C:/Program Files/chromedriver.exe")
driver.get(url)
sleep(randint(5,15))
soup = BeautifulSoup(driver.page_source, 'html.parser')
body=soup.body.text
body
body= body.replace('\n', ' ')
body= body.replace('\t', ' ')
body= body.replace('\r', ' ')
body= body.replace('\xa0', ' ')
text3= NER(body)
displacy.render(text3,style="ent",jupyter=True)
The output is shown as:
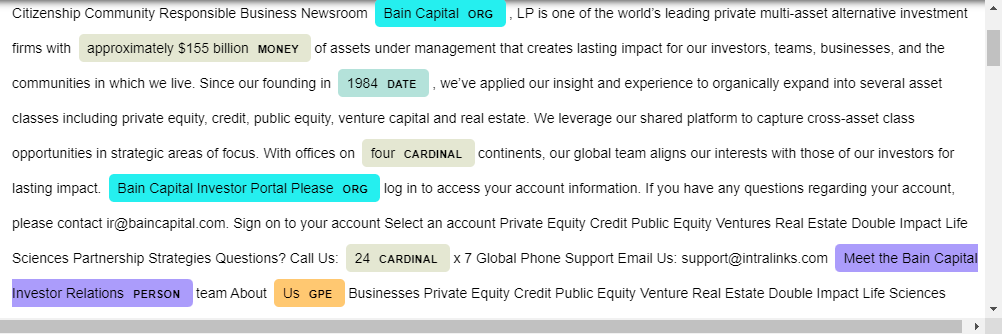
And I would like to place it in the following rudimentary table:
| Entity | Identified |
|---|---|
| Money | $155 Billion |
| Date | 1984 |
| Org | Bain Capital |
| Org | Bain Capital Investor Portal Please |
| Cardinal | four |
| Cardinal | 24 |
| GPE | US |
Essentially, take highlighted info and place it in a dataframe with identifying features.
CodePudding user response:
After you obtained the body with plain text, you can parse the text into a document and get a list of all entities with their labels and texts, and then instantiate a Pandas dataframe with those data:
#... your code here ...
body=soup.body.text
# now, this is the modification:
body = ' '.join(body.split())
doc = NER(body)
entities = [(e.label_,e.text) for e in doc.ents]
df = pd.DataFrame(entities, columns=['Entity','Identified'])
Note that the body = ' '.join(body.split()) line is used to normalize all whitespace in a simpler and shorter way than you used.