import scrapy
from scrapy.http import Request
class PushpaSpider(scrapy.Spider):
name = 'pushpa'
start_urls = ['http://smartcatalog.emo-milano.com/it/catalogo/elenco-alfabetico/400/A']
def parse(self, response):
for link in response.xpath("//div[@class='exbox-name']/a/@href"):
yield response.follow(link.get(),callback=self.parse_book)
def parse_book(self, response):
rows = response.xpath('//table[@]//tr')
table = {}
for row in rows:
key = row.xpath('.//td[1]//text()').get(default='').strip()
value = row.xpath('.//td[2]/text() ').getall()
value = ''.join(value).strip()
table.update({key: value})
yield table
I am trying to scrape table but they will not give the information of Telefono,Fax,Email,Membro di,Social check these
{'Indirizzo': 'Dr.-Auner-Str. 21a', 'Città': 'Raaba / Graz', 'Nazionalità': 'Austria', 'Sito web': '', 'Stand': 'Pad. 5 B22 C27', 'Telefono': '', 'Fax': '', 'E-mail': '', 'Social': ''}
the link of page is 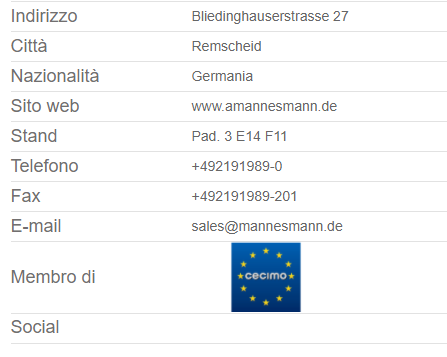
CodePudding user response:
The values for telephone and fax etc are in an a tag therefore you need to adjust your xpath selectors to account for those cases.
See below sample
import scrapy
class PushpaSpider(scrapy.Spider):
name = 'pushpa'
start_urls = ['http://smartcatalog.emo-milano.com/it/catalogo/elenco-alfabetico/400/A']
custom_settings = {
'USER_AGENT': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.99 Safari/537.36'
}
def parse(self, response):
for link in response.xpath("//div[@class='exbox-name']/a/@href"):
yield response.follow(link.get(),callback=self.parse_book)
def parse_book(self, response):
rows = response.xpath('//table[@]/tr')
table = {}
for row in rows:
key = row.xpath('./td[1]//text()').get(default='').strip()
value = row.xpath('./td[2]/text() ').getall()
value = ''.join(value).strip()
if not value:
value = row.xpath('./td[2]/a/text() ').getall()
value = ''.join(value).strip()
table.update({key: value})
yield table