I have a dataframe like as shown below
import numpy as np import pandas as pd np.random.seed(100)
df = pd.DataFrame({'grade': np.random.choice(list('ABCD'),size=(20)),
'dash': np.random.choice(list('PQRS'),size=(20)),
'dumeel': np.random.choice(list('QWER'),size=(20)),
'dumma': np.random.choice((1234),size=(20)),
'target': np.random.choice([0,1],size=(20))
})
I would like to do the below
a) event rate - Compute the % occurrence of 1s (from target column) for each unique value in a each of the input categorical column
b) non event rate - Compute the % occurrence of 0s (from target column) for each unique value in each of the input categorical columns
c) no of events - Compute the number of records of 1's (from target column) for each unique value in each of the input categorical column
d) no of non events - Compute the number of records of 0's (from target column) for each unique value in each of the input categorical column
With the help of Shubham, am able to compute the % using the below code
cols = df.select_dtypes('object')
df_out = (
df.melt('target', cols)
.groupby(['variable', 'target'])['value']
.value_counts(normalize=True)
.unstack(1, fill_value=0)
)
But now, along with the %, I would also like to get the count or no of records for each unique value in the categorical value
I expect my output to be like as shown below
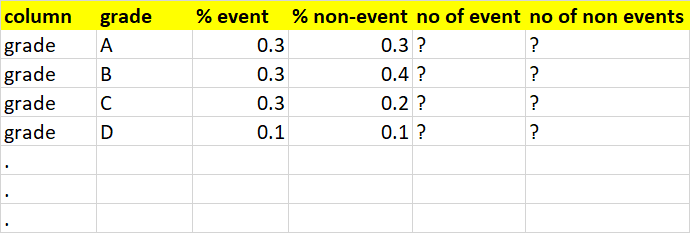
CodePudding user response:
Here is one approach:
- Select the catgorical columns (
cols) Meltthe dataframe withtargetas id variable andcolsas value variables- Create frequency table (
counts) usinggroupbyvalue_counts - Normalize the
countstable along the columns axis to create (counts_norm) - Concat
countsandcounts_norm - Reshape the dataframe using stack, unstack
cols = df.select_dtypes('object')
counts = (
df.melt('target', cols)
.groupby(['variable', 'target'])['value']
.value_counts().unstack()
)
counts_norm = counts.div(counts.sum(1), axis=0)
df_out = pd.concat([counts, counts_norm], keys=['N', '%_N'])\
.stack().unstack([0, 2], fill_value=0)
print(df_out)
N %_N
target 0 1 0 1
variable value
dash P 4.0 3.0 0.4 0.3
Q 2.0 3.0 0.2 0.3
R 2.0 1.0 0.2 0.1
S 2.0 3.0 0.2 0.3
dumeel E 2.0 2.0 0.2 0.2
Q 1.0 0.0 0.1 0.0
R 4.0 6.0 0.4 0.6
W 3.0 2.0 0.3 0.2
grade A 4.0 2.0 0.4 0.2
B 0.0 2.0 0.0 0.2
C 4.0 3.0 0.4 0.3
D 2.0 3.0 0.2 0.3
CodePudding user response:
I've got a working example for you. After trying to use the 