I have a data frame in pandas like this:
Name Date
A 9/1/21
B 10/20/21
C 9/8/21
D 9/20/21
K 9/29/21
K 9/15/21
M 10/1/21
C 9/12/21
D 9/9/21
C 9/9/21
R 9/20/21
I need to get the count of items by week.
weeks = [9/6/21, 9/13, 9/20/21, 9/27/21, 10/4/21]
Example: From 9/6 to 9/13, the output should be:
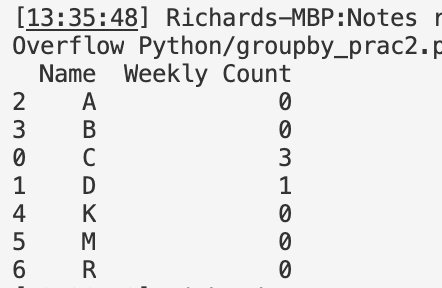
Name Weekly count
A 0
B 0
C 3
D 1
M 0
K 0
R 0
Similarly, I need to find the count on these intervals: 9/13 to 9/20, 9/20 to 9/27, and 9/27 to 10/4. Thank you!
CodePudding user response:
Here is my very rough solution to how to handle a problem like this. I only handle the first range of weeks to demonstrate how it works, but you can easily loop through weeks (replace weeks[0] and weeks[1] with weeks[i] and weeks[i 1] in the loop) and get the rest of the results:
import pandas as pd
from datetime import datetime
d = {"Name": ["A", "B", "C", "D", "K", "K", "M", "C", "D", "C", "R"],
"Date": ["9/1/21", "10/20/21", "9/8/21", " 9/20/21","9/29/21","9/15/21","10/1/21","9/12/21","9/9/21","9/9/21","9/20/21"]}
df = pd.DataFrame(data=d)
df_copy = df.copy()
weeks = ["9/6/21", "9/13/21", "9/20/21", "9/27/21", "10/4/21"]
df['Date'] = pd.to_datetime(df['Date'])
mask = (df['Date'] >= datetime.strptime(weeks[0], "%m/%d/%y")) & (df['Date'] <= datetime.strptime(weeks[1],"%m/%d/%y"))
df = df.loc[mask]
out = df.groupby('Name').count().reset_index()
for row in df_copy.iterrows():
if row[1]["Name"] not in list(out["Name"]):
#print(row[1]["Name"])
to_add = {"Name": row[1]["Name"], "Date" : 0}
out = out.append(to_add, ignore_index=True)
out = out.sort_values(by=['Name']).rename(columns={"Date":"Weekly Count"})
print(out)
Note: There is probably a much cleaner way to do this other than adding the rows with 0 matching weeks back in at the end, but I do not know how.
Output: