I started from a csv file, converted to the dataframe below:
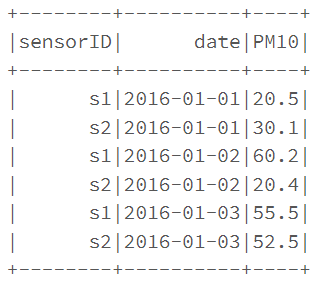
Continuing to work on dataframe and using PYSPARK, I need to find values in the sensorID column that have at least two records that satisfy the condition (PM10 > 50).
Then, I need to have an output with the value of sensorID and a count of how many times the condition is met.
The output should be: sensorID: s1; 2 (count of PM10>50)
I tried:
rdd.select("sensorID").where(col("PM10") > 50).count().show()
that gives me an error.
I tried without .show(), but I can't select only the value with at least two records (I tried groupBy and orderBy, but it's always wrong).
I'm having a problem putting them together properly. I hope you can explain to me where I am going wrong, thanks.
CodePudding user response:
Use conditional sum aggregation:
import pyspark.sql.functions as F
df = spark.createDataFrame([
("s1", "2016-01-01", 20.5), ("s2", "2016-01-01", 30.1), ("s1", "2016-01-02", 60.2),
("s2", "2016-01-02", 20.4), ("s1", "2016-01-03", 55.5), ("s2", "2016-01-03", 52.5)
], ["sensorId", "date", "PM10"])
df1 = df.groupBy("sensorId").agg(
F.sum(F.when(F.col("PM10") > 50., 1)).alias("count")
).filter("count > 1")
df1.show()
# -------- -----
#|sensorId|count|
# -------- -----
#| s1| 2|
# -------- -----