I have a crappy dataset which I got from 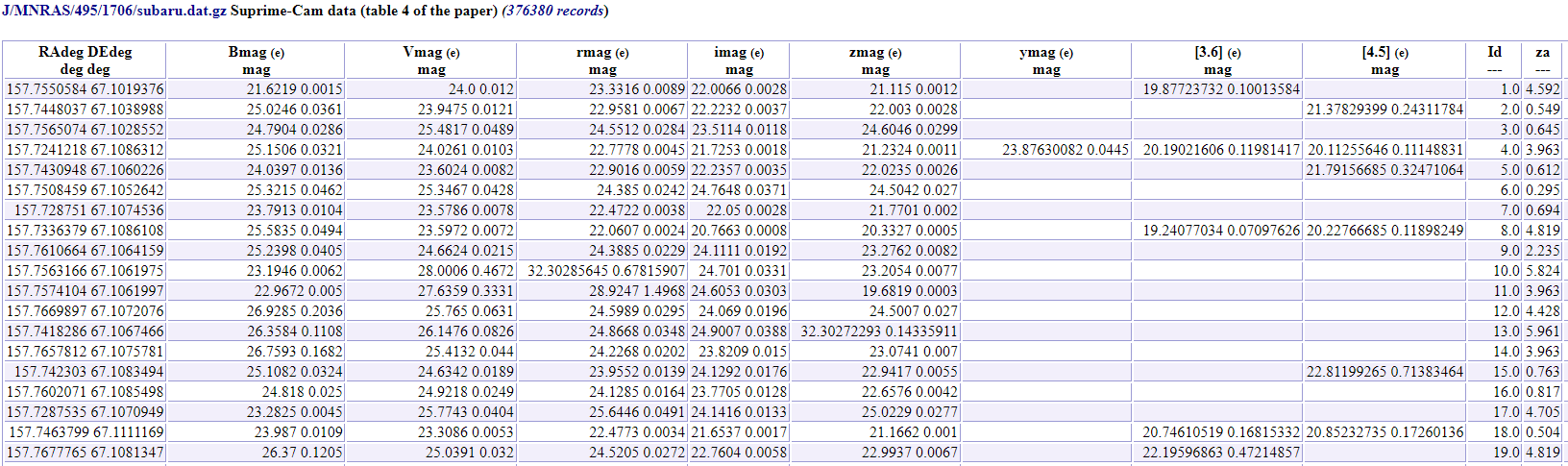 but when I download the file, it contains extra spaces as padding, as well as where there is missing data. This means that I can't use Python's
but when I download the file, it contains extra spaces as padding, as well as where there is missing data. This means that I can't use Python's .replace method to change the spaces to NAs. After downloading the original file, I replace the spaces with commas using this script:
with open("./emerlin_vla_subaru/subaru.dat", 'r') as f:
a=f.readlines()
with open("./emerlin_vla_subaru/subaru_fixed.dat" ,"w ") as f:
for i in range(len(a)):
c=a[i].split()
f.write(",".join(c))
f.write("\n")
but this method deletes the missing cells and shifts the data to the left to fill the blanks. I tried using R, but it doesn't realize that there are those blank cells in the middle of the data. Does anyone know how I can clean up the data, or find an already tidied version?
CodePudding user response:
In R, you can install.packages("rvest") and use
x <- (rvest::read_html("subaru.dat.gz") |> rvest::html_table())[[1L]]
to get the data into a dataframe without loss. The only thing you need is RAM since R is quite a RAM-intensive language, and your HTML file is very large. It takes about 5 mins to read the data into memory. The whole process peaked at slightly more than 14 GiB memory usage on my laptop.
The output should look like this
> x
# A tibble: 376,380 x 28
`RAdeg DEdegdeg ~ `Bmag (e)mag` `Vmag (e)mag` `rmag (e)mag` `imag (e)mag` `zmag (e)mag` `ymag (e)mag` `[3.6] (e)mag`
<chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 157.7550584 67.~ 21.6219 ~ 24.0 ~ 23.3316 ~ 22.0066 ~ 21.115 ~ "" "19.87723732 ~
2 157.7448037 67.~ 25.0246 ~ 23.9475 ~ 22.9581 ~ 22.2232 ~ 22.003 ~ "" ""
3 157.7565074 67.~ 24.7904 ~ 25.4817 ~ 24.5512 ~ 23.5114 ~ 24.6046 ~ "" ""
4 157.7241218 67.~ 25.1506 ~ 24.0261 ~ 22.7778 ~ 21.7253 ~ 21.2324 ~ "23.87630082~ "20.19021606 ~
5 157.7430948 67.~ 24.0397 ~ 23.6024 ~ 22.9016 ~ 22.2357 ~ 22.0235 ~ "" ""
6 157.7508459 67.~ 25.3215 ~ 25.3467 ~ 24.385 ~ 24.7648 ~ 24.5042 ~ "" ""
7 157.728751 67.~ 23.7913 ~ 23.5786 ~ 22.4722 ~ 22.05 ~ 21.7701 ~ "" ""
8 157.7336379 67.~ 25.5835 ~ 23.5972 ~ 22.0607 ~ 20.7663 ~ 20.3327 ~ "" "19.24077034 ~
9 157.7610664 67.~ 25.2398 ~ 24.6624 ~ 24.3885 ~ 24.1111 ~ 23.2762 ~ "" ""
10 157.7563166 67.~ 23.1946 ~ 28.0006 ~ 32.30285645 ~ 24.701 ~ 23.2054 ~ "" ""
# ... with 376,370 more rows, and 20 more variables: [4.5] (e)mag <chr>, Id--- <dbl>, za--- <dbl>, chiza--- <dbl>,
# (e) (E) <chr>, (e) (E) <chr>, Nfilt--- <dbl>, e1--- <dbl>, e2--- <dbl>, Radpix <dbl>, RadRatio--- <dbl>,
# BulgeA--- <dbl>, DiscA--- <dbl>, BulgeIndex--- <dbl>, DiscIndex--- <dbl>, BulgeFlux--- <dbl>, DiscFlux--- <dbl>,
# FluxRatio--- <dbl>, snr--- <dbl>, SourceId--- <chr>
Performance measurement
> system.time(x <- (rvest::read_html("subaru.dat.gz") |> rvest::html_table())[[1L]])
user system elapsed
288.75 2.72 291.62