I'm training a model through Tensorflow and evaluating via Tensorboard. This is my total loss function:
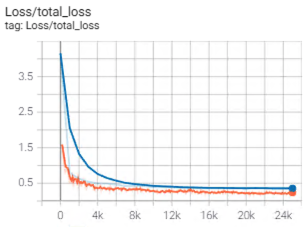
Can anybody tell me what the unit of the y-axis is? At first instance I thought it would be a proportion, but then you wouldn't expect it starting from > 4. I understand this is a combination of the classification loss and the localisation loss, but even the classification loss alone starts from > 3.
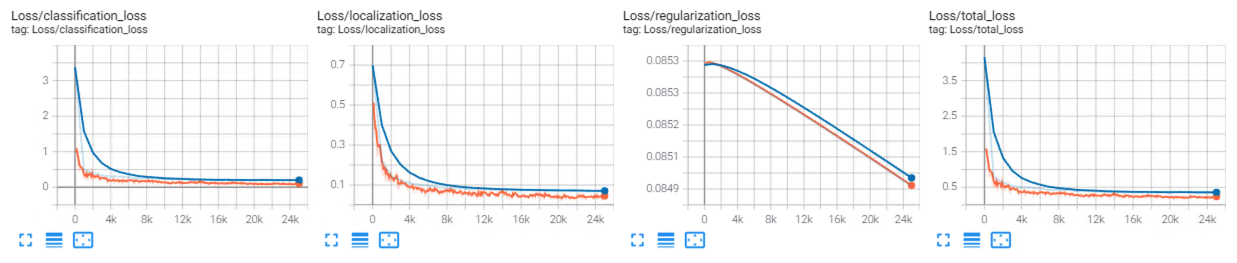
Im training trough the terminal command:
set NVIDIA_VISIBLE_DEVICES=0 & set CUDA_VISIBLE_DEVICES=0 & python object_detection/model_main_tf2.py --pipeline_config_path="V:/Projecten/A70_30_65/Marterkist/Model/ssd_mobilenet_v2_320x320_coco17_tpu-8.config" --model_dir="V:/Projecten/A70_30_65/Marterkist/Training" --alsologtostderr
And evaluating via the terminal command:
python object_detection/model_main_tf2.py --pipeline_config_path="V:/Projecten/A70_30_65/Marterkist/Model/ssd_mobilenet_v2_320x320_coco17_tpu-8.config" --model_dir="V:/Projecten/A70_30_65/Marterkist/Training" --checkpoint_dir="V:/Projecten/A70_30_65/Marterkist/Training" --alsologtostderr
This is the associated .config file:
# SSD with Mobilenet v2
# Trained on COCO17, initialized from Imagenet classification checkpoint
# Train on TPU-8
#
# Achieves 22.2 mAP on COCO17 Val
model {
ssd {
inplace_batchnorm_update: true
freeze_batchnorm: false
num_classes: 7
box_coder {
faster_rcnn_box_coder {
y_scale: 10.0
x_scale: 10.0
height_scale: 5.0
width_scale: 5.0
}
}
matcher {
argmax_matcher {
matched_threshold: 0.5
unmatched_threshold: 0.5
ignore_thresholds: false
negatives_lower_than_unmatched: true
force_match_for_each_row: true
use_matmul_gather: true
}
}
similarity_calculator {
iou_similarity {
}
}
encode_background_as_zeros: true
anchor_generator {
ssd_anchor_generator {
num_layers: 6
min_scale: 0.2
max_scale: 0.95
aspect_ratios: 1.0
aspect_ratios: 2.0
aspect_ratios: 0.5
aspect_ratios: 3.0
aspect_ratios: 0.3333
}
}
image_resizer {
fixed_shape_resizer {
height: 300
width: 300
}
}
box_predictor {
convolutional_box_predictor {
min_depth: 0
max_depth: 0
num_layers_before_predictor: 0
use_dropout: false
dropout_keep_probability: 0.8
kernel_size: 1
box_code_size: 4
apply_sigmoid_to_scores: false
class_prediction_bias_init: -4.6
conv_hyperparams {
activation: RELU_6,
regularizer {
l2_regularizer {
weight: 0.00004
}
}
initializer {
random_normal_initializer {
stddev: 0.01
mean: 0.0
}
}
batch_norm {
train: true,
scale: true,
center: true,
decay: 0.97,
epsilon: 0.001,
}
}
}
}
feature_extractor {
type: 'ssd_mobilenet_v2_keras'
min_depth: 16
depth_multiplier: 1.0
conv_hyperparams {
activation: RELU_6,
regularizer {
l2_regularizer {
weight: 0.00004
}
}
initializer {
truncated_normal_initializer {
stddev: 0.03
mean: 0.0
}
}
batch_norm {
train: true,
scale: true,
center: true,
decay: 0.97,
epsilon: 0.001,
}
}
override_base_feature_extractor_hyperparams: true
}
loss {
classification_loss {
weighted_sigmoid_focal {
alpha: 0.75,
gamma: 2.0
}
}
localization_loss {
weighted_smooth_l1 {
delta: 1.0
}
}
classification_weight: 1.0
localization_weight: 1.0
}
normalize_loss_by_num_matches: true
normalize_loc_loss_by_codesize: true
post_processing {
batch_non_max_suppression {
score_threshold: 1e-8
iou_threshold: 0.6
max_detections_per_class: 100
max_total_detections: 100
}
score_converter: SIGMOID
}
}
}
train_config: {
fine_tune_checkpoint_version: V2
fine_tune_checkpoint: "V:/Projecten/A70_30_65/Marterkist/Model/ssd_mobilenet_v2_320x320_coco17_tpu-8/checkpoint/ckpt-0"
fine_tune_checkpoint_type: "detection"
batch_size: 32
sync_replicas: true
startup_delay_steps: 0
replicas_to_aggregate: 8
num_steps: 25000
optimizer {
momentum_optimizer: {
learning_rate: {
manual_step_learning_rate {
initial_learning_rate: 0.0003
schedule {
step: 20000
learning_rate: 0.0003
}
}
}
momentum_optimizer_value: 0.9
}
use_moving_average: false
}
max_number_of_boxes: 100
unpad_groundtruth_tensors: false
}
train_input_reader: {
label_map_path: "V:/Projecten/A70_30_65/Marterkist/Model/labelmap.pbtxt"
tf_record_input_reader {
input_path: "V:/Projecten/A70_30_65/Marterkist/Data/Train/train.record"
}
}
eval_config: {
metrics_set: "coco_detection_metrics"
use_moving_averages: false
}
eval_input_reader: {
label_map_path: "V:/Projecten/A70_30_65/Marterkist/Model/labelmap.pbtxt"
shuffle: false
num_epochs: 1
tf_record_input_reader {
input_path: "V:/Projecten/A70_30_65/Marterkist/Data/Train/test.record"
}
}
CodePudding user response:
The relevant part of your config is this:
loss {
classification_loss {
weighted_sigmoid_focal {
alpha: 0.75,
gamma: 2.0
}
}
localization_loss {
weighted_smooth_l1 {
delta: 1.0
}
}
classification_weight: 1.0
localization_weight: 1.0
}
classification_weight = localization_weight = 1 means that the total loss is just a sum of the classification and localization losses. weighted_sigmoid_focal classification loss is calculated as -alpha*(1 - p)**gamma*log(p), where p is a class probability (see details in the article referenced by https://www.tensorflow.org/addons/api_docs/python/tfa/losses/SigmoidFocalCrossEntropy). It is hard to assign some easy-to-interpret sense to it. And weighted_smooth_l1 localization loss is the same as Huber loss, which is not easily interpretable either.
All the above boils down to following: the absolute values you see don't have any easily understandable meaning. It is only relative changes that matter: does the loss increase or decrease etc.