I am writing some macros that call Python code to perform operations on ranges in Excel. It is much easier to do a lot of the required operations with pandas in Python. Because I want to do this while the spreadsheet is open (and may not have been saved), I am using the win32com.client to read in a range of cells to convert to a Pandas dataframe. However, this is extremely slow, presumably because the way I calculate it is very inefficient:
import datetime
import pytz
import pandas
import time
import win32com.client
def range_to_table(excelRange, tsy, tsx, height, width, add_cell_refs = True):
ii = 0
keys = []
while ii < width:
keys.append(str(excelRange[ii]))
ii = 1
colnumbers = {key:jj tsx for jj, key in enumerate(keys)}
keys.append('rownumber')
mydict = {key:[] for key in keys}
while ii < width*height:
mydict[keys[ii%width]].append(excelRange[ii].value)
ii = 1
for yy in range(tsy 1, tsy 1 height - 1): # add 1 to not include header
mydict['rownumber'].append(yy)
return (mydict, colnumbers)
ExcelApp = win32com.client.GetActiveObject('Excel.Application')
wb = ExcelApp.Workbooks('myworkbook.xlsm')
sheet_num = [sheet.Name for sheet in wb.Sheets].index("myworksheet name") 1
ws = wb.Worksheets(sheet_num)
height = int(ws.Cells(1, 3)) # obtain table height from formula in excel spreadsheet
width = int(ws.Cells(1, 2)) # obtain table width from formula in excel spreadsheet
myrange = ws.Range(ws.Cells(2, 1), ws.Cells(2 height - 1, 1 width - 1))
df, colnumbers = range_to_table(myrange, 1, 1, height, width)
df = pandas.DataFrame.from_dict(df)
This works, but the range_to_table function I wrote is extremely slow for large tables since it iterates over each cell one by one.
I suspect there is probably a much better way to convert the Excel Range object to a Pandas dataframe. Do you know of a better way?
Here a simplified example of what my range would look like:
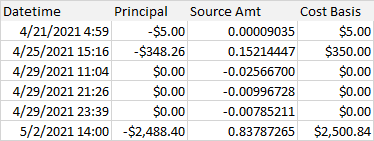
The height and width variables in the code are just taken from cells immediately above the table:
Any ideas here, or am I just going to have to save the workbook and use Pandas to read in the table from the saved file?
CodePudding user response:
There are two parts to the operation: defining the spreadsheet range and then getting the data into Python. Here is the test data that I'm working with:
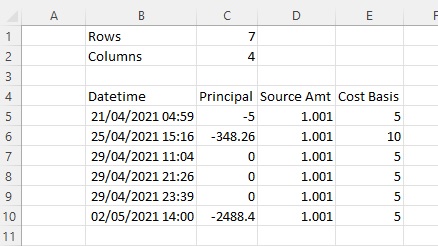
1. Defining the range: Excel has a feature called 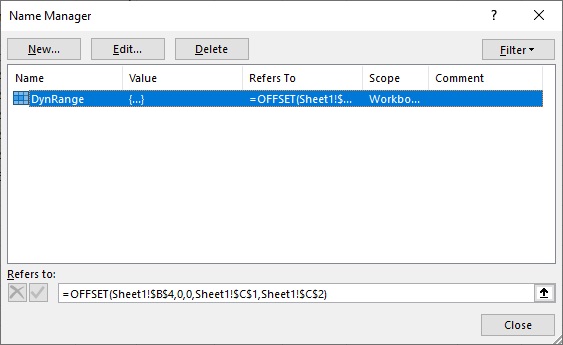
Once you have this definition, the range can be used by Name in Python, and saves you having to access the row and column count explicitly.
2. Using this range in Python via win32.com: Once you have defined the name in Excel, handling it in Python is much easier.
import win32com.client as wc
import pandas as pd
#Create a dispatch interface
xl = wc.gencache.EnsureDispatch('Excel.Application')
filepath = 'SomeFilePath\\TestBook.xlsx'
#Open the workbook
wb = xl.Workbooks.Open(filepath)
#Get the Worksheet by name
ws = wb.Sheets('Sheet1')
#Use the Value property to get all the data in the range
#and then unpack the tuple-of-tuples into a list-of-lists
listVals = [[*row] for row in ws.Range('DynRange').Value]
#Construct the dataframe, using first row as headers
df = pd.DataFrame(listVals[1:],columns=listVals[0])
#Optionally process the datetime value to avoid tz warnings
df['Datetime'] = df['Datetime'].dt.tz_convert(None)
print(df)
wb.Close()
Output:
Datetime Principal Source Amt Cost Basis
0 2021-04-21 04:59:00 -5.0 1.001 5.0
1 2021-04-25 15:16:00 -348.26 1.001 10.0
2 2021-04-29 11:04:00 0.0 1.001 5.0
3 2021-04-29 21:26:00 0.0 1.001 5.0
4 2021-04-29 23:39:00 0.0 1.001 5.0
5 2021-05-02 14:00:00 -2488.4 1.001 5.0
As the OP suspects, iterating over the range cell-by-cell performs slowly. The COM infrastructure has to do a good deal of processing to pass data from one process (Excel) to another (Python). This is known as 'marshalling'. Most of the time is spent packing up the variables on one side and unpacking on the other. It is much more efficient to marshal the entire contents of an Excel Range in one go (as a 2D array) and Excel allows this by exposing the Value property on the Range as a whole, rather than by cell.
CodePudding user response:
You can try using multiprocessing for this. You could have each worker scanning a different column for example, or even do the same on the lines.
Minor changes to your code are needed:
- Create a function iterating over the columns and storing the information in a dict
- Use the simple multiprocessing example @ https://pymotw.com/2/multiprocessing/basics.html
- Create a function appending all different dicts created by each worker into a single one
That should divide your compute time by the amount of workers used.