I have a data frame that contains 5000 examinee's ability estimation with their test score, and they are both continuous variables. Since there are too many examinees, it would be messy to plot out all their scores, so I wish to draw a 'broken line plot' or 'conditional mean plot', that average the test scores of several examines that have similar ability levels at a time, and plot their average score against their average ability. Like the plot below.
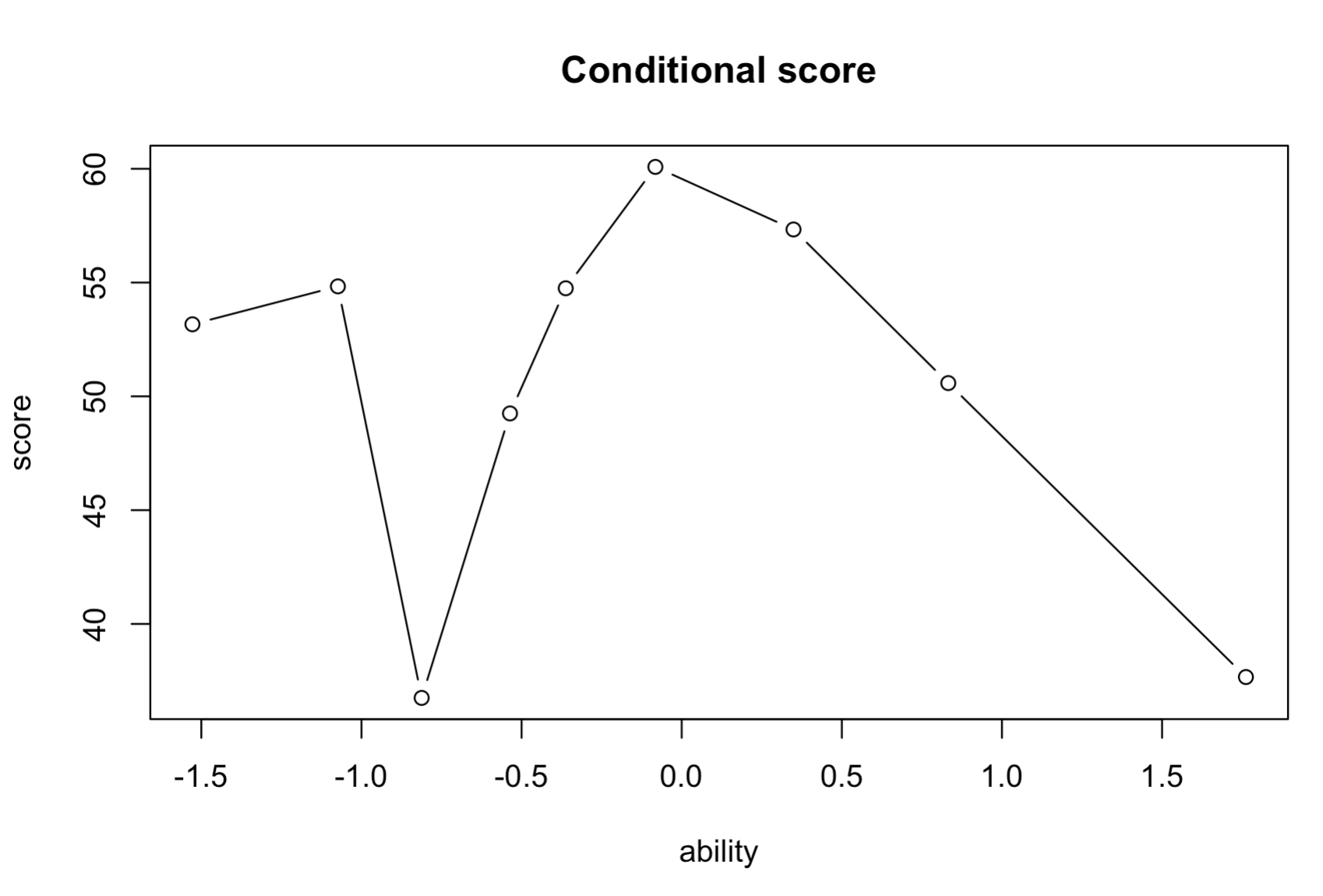
I already managed to do this with the codes below.
df<-cbind(rnorm(100,set.seed(123)),sample(100,set.seed(123)),) %>%
as.data.frame() %>%
setNames(c("ability","score")) #simulate the dataset
df<-df[order(df$ability),] #sort the data from low to high according to the ability varaible
seq<-round(seq(from=1, to=nrow(df), length.out=10),0) #divide the data equally to nine groups (which is also gonna be the 9 points that appear in my plot)
b<-data.frame()
for (i in 1:9) {
b[i,1]<-mean(df[seq[i]:seq[i 1],1]) #calculate the mean of the ability by group
b[i,2]<-mean(df[seq[i]:seq[i 1],2]) # calculate the mean of test score by group
}.
I got the mean of the ability and test score using this for loop, and it looks like this
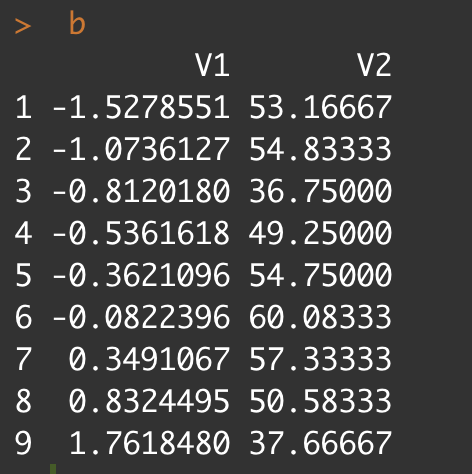
and finally, do the plot
plot(b$V1,b$V2, type='b',
xlab="ability",
ylab="score",
main="Conditional score")
These codes meet my goal, but I can't help thinking if there's a simpler way to do this. Drawing a broken line plot by averaging the data that is sorted from low to high seems to be a normal task. I wonder if there is any function or trick for this. All ideas are welcome! :)
CodePudding user response:
Here is a solution to create the data to be plotted using dplyr:
set.seed(123)
df<-cbind(rnorm(100,1),sample(100,50)) %>%
as.data.frame() %>%
setNames(c("ability","score")) #simulate the dataset
df<-df[order(df$ability),] #sort the data from low to high according to the ability varaible
df$id <- seq(1, nrow(df))
df %>% mutate(bin = ntile(id, 10)) %>%
group_by(bin) %>%
dplyr::summarize(meanAbility = mean(ability, na.rm=T),
meanScore = mean(score, na.rm=T)) %>%
as.data.frame()
bin meanAbility meanScore
1 1 -0.81312770 41.6
2 2 -0.09354171 52.3
3 3 0.29089892 54.4
4 4 0.68490709 45.8
5 5 0.93078744 59.8
6 6 1.17380069 34.0
7 7 1.42942368 41.3
8 8 1.64965315 40.1
9 9 1.95290596 35.6
10 10 2.50277510 52.9
CodePudding user response:
I would approach the whole thing a bit differently (note also that your code has several errors and won't run the way you were showing.
The exmaple below will lead to different numbers than yours (due to the random generation of numbers and your non-working code).
library(tidyverse)
df <- data.frame(ability = rnorm(100),
score = sample(100)) %>%
arrange(ability) %>%
mutate(seq = ntile(n = 9)) %>%
group_by(seq) %>%
summarize(mean_ability = mean(ability),
mean_score = mean(score))
which gives:
# A tibble: 9 x 3
seq mean_ability mean_score
<int> <dbl> <dbl>
1 1 -1.390807 45.25
2 2 -0.7241746 56.18182
3 3 -0.4315872 49
4 4 -0.2223723 48.81818
5 5 0.06313174 56.36364
6 6 0.3391321 42
7 7 0.6118022 53.27273
8 8 1.021438 50.54545
9 9 1.681746 53.54545