I am trying to pivot a table that has headings and sub-headings, so that the headings go into a column "date", and the subheadings are two columns instead of repeating.
Here is an example of my data.
This was produced using dput(), so while in the original excel file, each date spanned over both sub-headings ("blue" and "green"), once in R, these blank cells were re-named X.1, X.2, etc.
table <- " X X.1 X02.Jul.12 X.2 X03.Jul.12 X.3 X04.Jul.12 X.4
1 category number blue green blue green blue green
2 G 1 1 0 1 0 1 0
3 G 2 2 99 2 99 1 99
4 G 3 1 1 1 99 1 99
5 G 4 1 1 1 1 2 99
6 G 5 1 0 1 0 1 99
7 G 6 1 99 1 1 1 99
8 G 7 1 0 1 0 1 0
9 G 8 1 1 1 1 1 99
10 G 9 1 1 1 1 1 1
11 H 1 1 1 1 1 1 1
12 H 2 1 99 1 0 1 0
13 H 3 1 1 1 1 1 99
14 H 4 1 99 1 2 1 99
15 H 5 1 1 1 1 1 1
16 H 6 1 0 1 0 1 99
17 H 7 1 1 2 1 1 99
18 H 8 2 0 2 0 1 1
19 H 9 2 0 2 0 1 1"
#Create a dataframe with the above table
df <- read.table(text=table, header = TRUE)
df
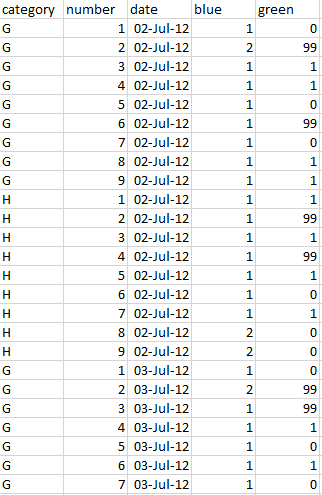
Here is an example of what it looks like in Excel:

This is the desired output I am trying to achieve:
While this can be done manually in Excel, I have multiple files with over 100 dates/columns, so would prefer to find a way to clean it in R.
Any help would be appreciated!
Excel Reprex
Here is a reprex of the dataset, as if it were read from Excel without name correction:
structure(
list(
c("category", "G", "G", "G", "G", "G", "G", "G", "G", "G", "H", "H", "H", "H", "H", "H", "H", "H", "H"),
c("number", "1", "2", "3", "4", "5", "6", "7", "8", "9", "1", "2", "3", "4", "5", "6", "7", "8", "9"),
`02.Jul.12` = c("blue", "1", "2", "1", "1", "1", "1", "1", "1", "1", "1", "1", "1", "1", "1", "1", "1", "2", "2"),
c("green", "0", "99", "1", "1", "0", "99", "0", "1", "1", "1", "99", "1", "99", "1", "0", "1", "0", "0"),
`03.Jul.12` = c("blue", "1", "2", "1", "1", "1", "1", "1", "1", "1", "1", "1", "1", "1", "1", "1", "2", "2", "2"),
c("green", "0", "99", "99", "1", "0", "1", "0", "1", "1", "1", "0", "1", "2", "1", "0", "1", "0", "0"),
`04.Jul.12` = c("blue", "1", "1", "1", "2", "1", "1", "1", "1", "1", "1", "1", "1", "1", "1", "1", "1", "1", "1"),
c("green", "0", "99", "99", "99", "99", "99", "0", "99", "1", "1", "0", "99", "99", "1", "99", "99", "1", "1")
),
class = "data.frame",
row.names = c("1", "2", "3", "4", "5", "6", "7", "8", "9", "10", "11", "12", "13", "14", "15", "16", "17", "18", "19")
)
CodePudding user response:
The following code should produce your desired output, though others may have more elegant solutions:
#Create a dataframe with the above table
df <- read.table(text=table, header = TRUE)
df
names(df) <- df[1,]
library(lubridate); library(tidyr)
startdate <- dmy("02-Jul-12")
for (i in seq(3, ncol(df), by = 2)){
names(df)[i:(i 1)] <- paste0(startdate, ":", names(df)[i:(i 1)])
startdate <- startdate 1
}
df.tdy <- df[-1,] %>% pivot_longer(-c("category","number"), names_to = "datecol", values_to = "value") %>%
separate(datecol, c("date","color"), sep = ":") %>%
pivot_wider(names_from = "color") %>%
arrange(date,category,number)
# category number date blue green
# <chr> <chr> <chr> <chr> <chr>
# 1 G 1 2012-07-02 1 0
# 2 G 2 2012-07-02 2 99
# 3 G 3 2012-07-02 1 1
# 4 G 4 2012-07-02 1 1
# 5 G 5 2012-07-02 1 0
# 6 G 6 2012-07-02 1 99
# 7 G 7 2012-07-02 1 0
# 8 G 8 2012-07-02 1 1
# 9 G 9 2012-07-02 1 1
# 10 H 1 2012-07-02 1 1
CodePudding user response:
Here is another option using a combination of base R and tidyverse. Here, I first clean up the column names by including the date in the column names for the column to the left (i.e., "green), so that each column has a date. Then, I concatenate the header with the sub-heading, except for the first 2 columns (i.e., category and number). Then, I remove the first row and pivot to a long format with the date in one column and the colors stay in their own column.
library(tidyverse)
colnames(df)[seq(2, ncol(df), 2)] <- colnames(df)[seq(1, ncol(df), 2)]
colnames(df) <-
c(df[1, 1], df[1, 2], paste(sep = '_', colnames(df)[3:ncol(df)], as.character(unlist(df[1, 3:ncol(df)]))))
df %>%
slice(-1) %>%
pivot_longer(-c(category, number),
names_to = c("Date", ".value"),
names_sep = "_") %>%
arrange(Date, category, number) %>%
mutate(Date = dmy(Date))
Output
# A tibble: 54 × 5
category number Date blue green
<chr> <chr> <date> <chr> <chr>
1 G 1 2012-07-02 1 0
2 G 2 2012-07-02 2 99
3 G 3 2012-07-02 1 1
4 G 4 2012-07-02 1 1
5 G 5 2012-07-02 1 0
6 G 6 2012-07-02 1 99
7 G 7 2012-07-02 1 0
8 G 8 2012-07-02 1 1
9 G 9 2012-07-02 1 1
10 H 1 2012-07-02 1 1
# … with 44 more rows
Data
df <- structure(
list(
c("category", "G", "G", "G", "G", "G", "G", "G", "G", "G", "H", "H", "H", "H", "H", "H", "H", "H", "H"),
c("number", "1", "2", "3", "4", "5", "6", "7", "8", "9", "1", "2", "3", "4", "5", "6", "7", "8", "9"),
`02.Jul.12` = c("blue", "1", "2", "1", "1", "1", "1", "1", "1", "1", "1", "1", "1", "1", "1", "1", "1", "2", "2"),
c("green", "0", "99", "1", "1", "0", "99", "0", "1", "1", "1", "99", "1", "99", "1", "0", "1", "0", "0"),
`03.Jul.12` = c("blue", "1", "2", "1", "1", "1", "1", "1", "1", "1", "1", "1", "1", "1", "1", "1", "2", "2", "2"),
c("green", "0", "99", "99", "1", "0", "1", "0", "1", "1", "1", "0", "1", "2", "1", "0", "1", "0", "0"),
`04.Jul.12` = c("blue", "1", "1", "1", "2", "1", "1", "1", "1", "1", "1", "1", "1", "1", "1", "1", "1", "1", "1"),
c("green", "0", "99", "99", "99", "99", "99", "0", "99", "1", "1", "0", "99", "99", "1", "99", "99", "1", "1")
),
class = "data.frame",
row.names = c("1", "2", "3", "4", "5", "6", "7", "8", "9", "10", "11", "12", "13", "14", "15", "16", "17", "18", "19")
)
CodePudding user response:
df %>%
set_names(enframe(unlist(df[1,])) %>%
mutate(name = na_if(name, ''))%>%
fill(name)%>%
transmute(nms = coalesce(str_c(name, value, sep='_'), value)) %>%
pull(nms)) %>%
slice(-1)%>%
type.convert(as.is = TRUE)%>%
pivot_longer(-c(category, number), names_to = c('Date', '.value'),
names_sep = '_', names_transform = list(Date = dmy)) %>%
arrange(category, Date, number)
# A tibble: 54 x 5
category number Date blue green
<chr> <int> <date> <int> <int>
1 G 1 2012-07-02 1 0
2 G 2 2012-07-02 2 99
3 G 3 2012-07-02 1 1
4 G 4 2012-07-02 1 1
5 G 5 2012-07-02 1 0
6 G 6 2012-07-02 1 99
7 G 7 2012-07-02 1 0
8 G 8 2012-07-02 1 1
9 G 9 2012-07-02 1 1
10 G 1 2012-07-03 1 0
# ... with 44 more rows
CodePudding user response:
Here's a tidyverse solution that doesn't rely on splicing any column names:
Solution
First import the tidyverse:
# Load the tidyverse.
library(tidyverse)
Then read the Excel file and extract the headers as manipulable rows.
# Read the Excel file as an unnamed dataset.
df <- readxl::read_xlsx("./reprex.xlsx", col_names = FALSE)
# Extract the dates (from the first row) and fill the blanks rightwards.
dates <- df[1, ] %>% t() %>% as_tibble() %>% fill(1, .direction = "down") %>% .[[1]]
# Extract the intended column names (from the second row).
names <- df[2, ] %>% t() %>% as.vector()
Finally, use this workflow to properly name and pivot the data.
# Cut out the headers from the data.
df <- df[-(1:2), ] %>%
# Properly name the dataset.
set_names(nm = names) %>%
# Pivot the color columns.
pivot_longer(cols = !c(category, number), names_to = "color") %>%
# Convert to the proper datatypes.
mutate(
category = as.character(category),
number = as.integer(number),
value = as.numeric(value)
) %>%
# Identify each "clump" of colors by the one row from which it originated;
# where {'category', 'number'} uniquely identify each such row.
group_by(category, number) %>%
# Map the date names to each clump.
mutate(
# Index the entries in each clump.
date = row_number(),
# Map each date to its corresponding entry.
date = dates[!is.na(dates)][date],
# Convert to date objects.
date = lubridate::as_datetime(date, format = "%d.%b.%y")
) %>% ungroup() %>%
# Pivot the colors into consolidated columns: one for each color.
pivot_wider(names_from = color, values_from = value) %>%
# Sort as desired.
arrange(date, category, number)
Results
Given a reprex.xlsx like that reproduced by this code
openxlsx::write.xlsx(
file = "./reprex.xlsx",
x = structure(
list(
c("category", "G", "G", "G", "G", "G", "G", "G", "G", "G", "H", "H", "H", "H", "H", "H", "H", "H", "H"),
c("number", "1", "2", "3", "4", "5", "6", "7", "8", "9", "1", "2", "3", "4", "5", "6", "7", "8", "9"),
"02.Jul.12" = c("blue", "1", "2", "1", "1", "1", "1", "1", "1", "1", "1", "1", "1", "1", "1", "1", "1", "2", "2"),
c("green", "0", "99", "1", "1", "0", "99", "0", "1", "1", "1", "99", "1", "99", "1", "0", "1", "0", "0"),
"03.Jul.12" = c("blue", "1", "2", "1", "1", "1", "1", "1", "1", "1", "1", "1", "1", "1", "1", "1", "2", "2", "2"),
c("green", "0", "99", "99", "1", "0", "1", "0", "1", "1", "1", "0", "1", "2", "1", "0","1", "0", "0"),
"04.Jul.12" = c("blue", "1", "1", "1", "2", "1", "1", "1", "1", "1", "1", "1", "1", "1", "1", "1", "1", "1", "1"),
c("green", "0", "99", "99", "99", "99", "99", "0", "99", "1", "1", "0", "99", "99", "1", "99", "99", "1", "1")
),
class = "data.frame",
row.names = c("1", "2", "3", "4", "5", "6", "7", "8", "9", "10", "11", "12", "13", "14", "15", "16", "17", "18", "19")
)
)
this solution should yield the following result for df:
# A tibble: 54 x 5
category number date blue green
<chr> <int> <dttm> <dbl> <dbl>
1 G 1 2012-07-02 00:00:00 1 0
2 G 2 2012-07-02 00:00:00 2 99
3 G 3 2012-07-02 00:00:00 1 1
4 G 4 2012-07-02 00:00:00 1 1
5 G 5 2012-07-02 00:00:00 1 0
6 G 6 2012-07-02 00:00:00 1 99
7 G 7 2012-07-02 00:00:00 1 0
8 G 8 2012-07-02 00:00:00 1 1
9 G 9 2012-07-02 00:00:00 1 1
10 H 1 2012-07-02 00:00:00 1 1
11 H 2 2012-07-02 00:00:00 1 99
12 H 3 2012-07-02 00:00:00 1 1
13 H 4 2012-07-02 00:00:00 1 99
14 H 5 2012-07-02 00:00:00 1 1
15 H 6 2012-07-02 00:00:00 1 0
16 H 7 2012-07-02 00:00:00 1 1
17 H 8 2012-07-02 00:00:00 2 0
18 H 9 2012-07-02 00:00:00 2 0
19 G 1 2012-07-03 00:00:00 1 0
20 G 2 2012-07-03 00:00:00 2 99
21 G 3 2012-07-03 00:00:00 1 99
22 G 4 2012-07-03 00:00:00 1 1
23 G 5 2012-07-03 00:00:00 1 0
24 G 6 2012-07-03 00:00:00 1 1
25 G 7 2012-07-03 00:00:00 1 0
26 G 8 2012-07-03 00:00:00 1 1
27 G 9 2012-07-03 00:00:00 1 1
28 H 1 2012-07-03 00:00:00 1 1
29 H 2 2012-07-03 00:00:00 1 0
30 H 3 2012-07-03 00:00:00 1 1
31 H 4 2012-07-03 00:00:00 1 2
32 H 5 2012-07-03 00:00:00 1 1
33 H 6 2012-07-03 00:00:00 1 0
34 H 7 2012-07-03 00:00:00 2 1
35 H 8 2012-07-03 00:00:00 2 0
36 H 9 2012-07-03 00:00:00 2 0
37 G 1 2012-07-04 00:00:00 1 0
38 G 2 2012-07-04 00:00:00 1 99
39 G 3 2012-07-04 00:00:00 1 99
40 G 4 2012-07-04 00:00:00 2 99
41 G 5 2012-07-04 00:00:00 1 99
42 G 6 2012-07-04 00:00:00 1 99
43 G 7 2012-07-04 00:00:00 1 0
44 G 8 2012-07-04 00:00:00 1 99
45 G 9 2012-07-04 00:00:00 1 1
46 H 1 2012-07-04 00:00:00 1 1
47 H 2 2012-07-04 00:00:00 1 0
48 H 3 2012-07-04 00:00:00 1 99
49 H 4 2012-07-04 00:00:00 1 99
50 H 5 2012-07-04 00:00:00 1 1
51 H 6 2012-07-04 00:00:00 1 99
52 H 7 2012-07-04 00:00:00 1 99
53 H 8 2012-07-04 00:00:00 1 1
54 H 9 2012-07-04 00:00:00 1 1
CodePudding user response:
A base R option using resahpe
u <- type.convert(setNames(df[-1, ], df[1, ]), as.is = TRUE)
transform(
reshape(
cbind(
u[1:2],
setNames(
u[-c(1:2)],
paste0(
names(u)[-c(1:2)],
".",
ave(seq(length(u) - 2), names(u)[-c(1:2)], FUN = seq_along)
)
)
),
direction = "long",
idvar = c("category", "number"),
varying = -c(1:2),
timevar = "date"
),
date = Filter(nchar, names(df))[date]
)
gives
category number date blue green
G.1.1 G 1 02.Jul.12 1 0
G.2.1 G 2 02.Jul.12 2 99
G.3.1 G 3 02.Jul.12 1 1
G.4.1 G 4 02.Jul.12 1 1
G.5.1 G 5 02.Jul.12 1 0
G.6.1 G 6 02.Jul.12 1 99
G.7.1 G 7 02.Jul.12 1 0
G.8.1 G 8 02.Jul.12 1 1
G.9.1 G 9 02.Jul.12 1 1
H.1.1 H 1 02.Jul.12 1 1
H.2.1 H 2 02.Jul.12 1 99
H.3.1 H 3 02.Jul.12 1 1
H.4.1 H 4 02.Jul.12 1 99
H.5.1 H 5 02.Jul.12 1 1
H.6.1 H 6 02.Jul.12 1 0
H.7.1 H 7 02.Jul.12 1 1
H.8.1 H 8 02.Jul.12 2 0
H.9.1 H 9 02.Jul.12 2 0
G.1.2 G 1 03.Jul.12 1 0
G.2.2 G 2 03.Jul.12 2 99
G.3.2 G 3 03.Jul.12 1 99
G.4.2 G 4 03.Jul.12 1 1
G.5.2 G 5 03.Jul.12 1 0
G.6.2 G 6 03.Jul.12 1 1
G.7.2 G 7 03.Jul.12 1 0
G.8.2 G 8 03.Jul.12 1 1
G.9.2 G 9 03.Jul.12 1 1
H.1.2 H 1 03.Jul.12 1 1
H.2.2 H 2 03.Jul.12 1 0
H.3.2 H 3 03.Jul.12 1 1
H.4.2 H 4 03.Jul.12 1 2
H.5.2 H 5 03.Jul.12 1 1
H.6.2 H 6 03.Jul.12 1 0
H.7.2 H 7 03.Jul.12 2 1
H.8.2 H 8 03.Jul.12 2 0
H.9.2 H 9 03.Jul.12 2 0
G.1.3 G 1 04.Jul.12 1 0
G.2.3 G 2 04.Jul.12 1 99
G.3.3 G 3 04.Jul.12 1 99
G.4.3 G 4 04.Jul.12 2 99
G.5.3 G 5 04.Jul.12 1 99
G.6.3 G 6 04.Jul.12 1 99
G.7.3 G 7 04.Jul.12 1 0
G.8.3 G 8 04.Jul.12 1 99
G.9.3 G 9 04.Jul.12 1 1
H.1.3 H 1 04.Jul.12 1 1
H.2.3 H 2 04.Jul.12 1 0
H.3.3 H 3 04.Jul.12 1 99
H.4.3 H 4 04.Jul.12 1 99
H.5.3 H 5 04.Jul.12 1 1
H.6.3 H 6 04.Jul.12 1 99
H.7.3 H 7 04.Jul.12 1 99
H.8.3 H 8 04.Jul.12 1 1
H.9.3 H 9 04.Jul.12 1 1
CodePudding user response:
Here is another solution using dplyr and tidyr. We would first combine the headers and subheaders and then pivot the data frame. We will do two pivoting operations: first collect everything into date, name (consisting of either "blue" or "green") and value (consisting of the corresponding values for "blue" and "green"); then, pivot_wider the name and value columns. df comes directly from your excel reprex.
library(dplyr)
library(tidyr)
nms1 <- tidyr:::fillDown(na_if(names(df), ""))
nms2 <- unlist(df[1L, ])
df[-1L, ] %>%
setNames(if_else(is.na(nms1), nms2, paste(nms1, nms2, sep = "_"))) %>%
pivot_longer(-c(category, number), c("date", "name"), names_sep = "_") %>%
pivot_wider()
Output
# A tibble: 54 x 5
category number date blue green
<chr> <chr> <chr> <chr> <chr>
1 G 1 02.Jul.12 1 0
2 G 1 03.Jul.12 1 0
3 G 1 04.Jul.12 1 0
4 G 2 02.Jul.12 2 99
5 G 2 03.Jul.12 2 99
6 G 2 04.Jul.12 1 99
7 G 3 02.Jul.12 1 1
8 G 3 03.Jul.12 1 99
9 G 3 04.Jul.12 1 99
10 G 4 02.Jul.12 1 1
# ... with 44 more rows