I have a df
df = pd.DataFrame({'group':['A','A','A','A','A',
'B','B','B','B','B',
'C','C','C','C','C'],
'category': ['zero','first', 'second', 'first second', 'total',
'zero', 'first', 'second', 'first second', 'total',
'zero','first', 'second', 'first second', 'total'],
'sales': [50,100,75,175,225,
5,10,15,25,30,
1000,2000,3000,3000,4000]})
I am trying to calculate the % of each category inside a group, the problem is that category first second and total is a sum of previous categories and should not be taken in to calculations.
I tried:
df['%'] = (df['sales'] / df.groupby(['group'])['sales'].transform('sum')) * 100
But now total is only 36% where it should be 100% and then then whole percentages are wrong.
If I isolate the groups like so:
my_df['%_v2'] =(my_df['sales'] / my_df[my_df.category.isin(['zero', 'first', 'second'])].groupby(['group'])['sales'].transform('sum')) * 100
Then zero, first, second % are correct, but I get nan in first second and total:
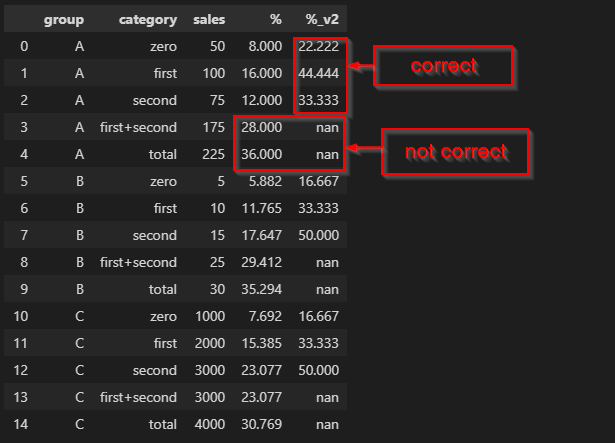
Instead of nan I would like to get the percentages of (175/225) * 100 for first second and 225/225 for total.
CodePudding user response:
Idea is replace not matched values by NaN in Series.where:
s = (df['sales'].where(df.category.isin(['zero', 'first', 'second']))
.groupby(df['group'])
.transform('sum'))
df['%'] = df['sales'].div(s).mul(100)
print (df)
group category sales %
0 A zero 50 22.222222
1 A first 100 44.444444
2 A second 75 33.333333
3 A first second 175 77.777778
4 A total 225 100.000000
5 B zero 5 16.666667
6 B first 10 33.333333
7 B second 15 50.000000
8 B first second 25 83.333333
9 B total 30 100.000000
10 C zero 1000 16.666667
11 C first 2000 33.333333
12 C second 3000 50.000000
13 C first second 3000 50.000000
14 C total 4000 100.000000