I have a result set with month as first column. Some of the month are missing in the result. I need to add previous month record as the missing month till last month.
Current data:
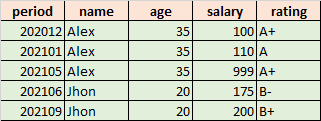
Desired Output:
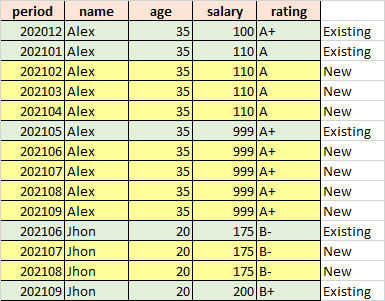
I have a sql but instead of filling for just missing month it is taking every rows into account and populate it.
select
to_char(generate_series(date_trunc('MONTH',to_date(period,'YYYYMMDD') interval '1' month),
date_trunc('MONTH',now() interval '1' day),
interval '1' month) - interval '1 day','YYYYMMDD') as period,
name,age,salary,rating
from( values ('20201205','Alex',35,100,'A '),
('20210110','Alex',35,110,'A'),
('20210512','Alex',35,999,'A '),
('20210625','Jhon',20,175,'B-'),
('20210922','Jhon',20,200,'B ')) v (period,name,age,salary,rating) order by 2,3,4,5,1;
Output of this query:
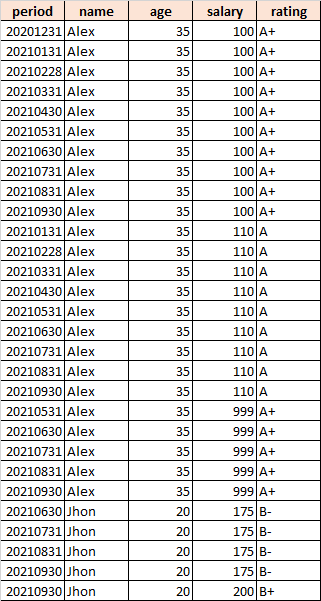
Can someone help in getting desired output.
Regards!!
CodePudding user response:
You can achieve this with a recursive cte like this:
with RECURSIVE ctetest as (SELECT * FROM (values ('2020-12-31'::date,'Alex',35,100,'A '),
('2021-01-31'::date,'Alex',35,110,'A'),
('2021-05-31'::date,'Alex',35,999,'A '),
('2021-06-30'::date,'Jhon',20,175,'B-'),
('2021-09-30'::date,'Jhon',20,200,'B ')) v (mth, emp, age, salary, rating)),
cte AS (
SELECT MIN(mth) AS mth, emp, age, salary, rating
FROM ctetest
GROUP BY emp, age, salary, rating
UNION
SELECT COALESCE(n.mth, (l.mth interval '1 day' interval '1 month' - interval '1 day')::date), COALESCE(n.emp, l.emp),
COALESCE(n.age, l.age), COALESCE(n.salary, l.salary), COALESCE(n.rating, l.rating)
FROM cte l
LEFT OUTER JOIN ctetest n ON n.mth = (l.mth interval '1 day' interval '1 month' - interval '1 day')::date
AND n.emp = l.emp
WHERE (l.mth interval '1 day' interval '1 month' - interval '1 day')::date <= (SELECT MAX(mth) FROM ctetest)
)
SELECT * FROM cte order by 2, 1;
Note that although ctetest is not itself recursive, being only used to get the test data, if any cte among multiple ctes are recursive, you must have the recursive keyword after the with.
CodePudding user response:
You can use cross join lateral to fill the gaps and then union all with the original data.
WITH the_table (period, name, age, salary, rating) as ( values
('2020-12-01'::date, 'Alex', 35, 100, 'A '),
('2021-01-01'::date, 'Alex', 35, 110, 'A'),
('2021-05-01'::date, 'Alex', 35, 999, 'A '),
('2021-06-01'::date, 'Jhon', 20, 100, 'B-'),
('2021-09-01'::date, 'Jhon', 20, 200, 'B ')
),
t as (
select *, coalesce(
lead(period) over (partition by name order by period) - interval 'P1M',
max(period) over ()
) last_period
from the_table
)
SELECT lat::date period, name, age, salary, rating
from t
cross join lateral generate_series
(period interval 'P1M', last_period, interval 'P1M') lat
UNION ALL
SELECT * from the_table
ORDER BY name, period;
Please note that using integer data type for a date column is sub-optimal. Better review your data design and use date data type instead. You can then present it as integer if necessary.
| period | name | age | salary | rating |
|---|---|---|---|---|
| 2020-12-01 | Alex | 35 | 100 | A |
| 2021-01-01 | Alex | 35 | 110 | A |
| 2021-02-01 | Alex | 35 | 110 | A |
| 2021-03-01 | Alex | 35 | 110 | A |
| 2021-04-01 | Alex | 35 | 110 | A |
| 2021-05-01 | Alex | 35 | 999 | A |
| 2021-06-01 | Alex | 35 | 999 | A |
| 2021-07-01 | Alex | 35 | 999 | A |
| 2021-08-01 | Alex | 35 | 999 | A |
| 2021-09-01 | Alex | 35 | 999 | A |
| 2021-06-01 | Jhon | 20 | 100 | B- |
| 2021-07-01 | Jhon | 20 | 100 | B- |
| 2021-08-01 | Jhon | 20 | 100 | B- |
| 2021-09-01 | Jhon | 20 | 200 | B |