I have a small cluster setup of Spark 3.x. I have read some data and after transformations, I have to save it as JSON. But the problem I am facing is that, in array type of columns, Spark is adding extra double quotes when written as json file.
Sample data-frame data

I am saving this data frame as JSON with following command
df.write.json("Documents/abc")
The saved output is as follows
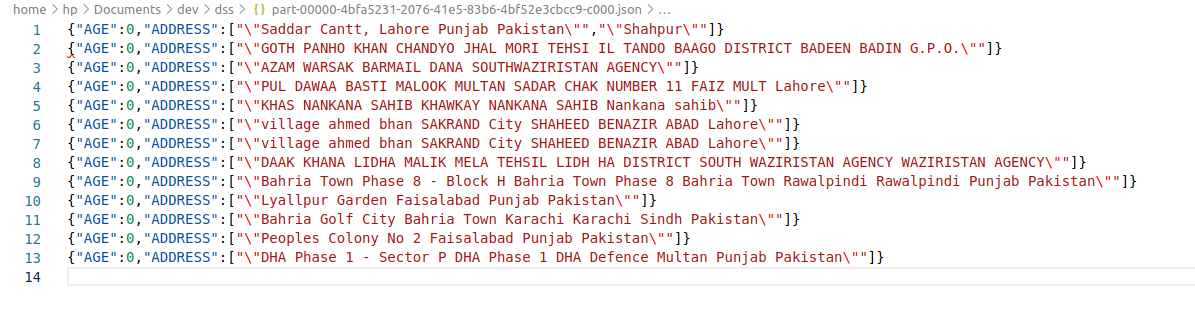
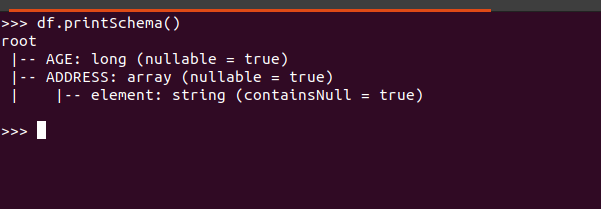
Finally, the schema info is as follows
CodePudding user response:
The elements of the string array contain double quotes within the data, e.g. the first element is "Saddar Cantt, Lahore Punjab Pakistan" instead of Saddar Cantt, Lahore Punjab Pakistan. You can remove the extra double quotes from the strings before writing the json with transform and replace:
df.withColumn("ADDRESS", F.expr("""transform(ADDRESS, a -> replace(a, '"'))""")) \
.write.json("Documents/abc")