I am trying to make web Scraper with Python and there is a problem in extracting title of company.
def extract_indeed_job():
jobs = []
result = requests.get(f"{url}&start={0*LIMIT}")
result_soup = BeautifulSoup(result.text, "html.parser")
results = result_soup.find_all("a", {"class": "tapItem"})
for result in results:
title = result.find("h2", {"class": "jobTitle"}).find("span")["title"]
company = result.find("span", {"class": "companyName"}).get_text()
location = result.find("div", {"class": "companyLocation"}).get_text()
print(title, company, location)
Some of posts, there are two span tags in the h2 class="jobTitle" tag 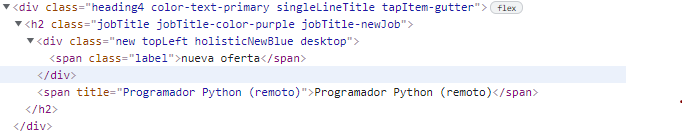
And I need to get just span title. So I wrote in with this tag. But, Python notices the key error and it doesn't work.
What can I do to solve? Is there any problem in my code??
CodePudding user response:
Note that there are multiple <span>s inside <h2> element. You want <span> which is immediate child of <h2> rather than <span> inside <div>, to get it you might replace
result.find("h2", {"class": "jobTitle"}).find("span")
using
result.find("h2", {"class": "jobTitle"}).find("span", recursive=False)
This will prevent recursive search (i.e. looking for children of children and further)
CodePudding user response:
the True ensure that you are filtering those span with that attribute so when you try to access to its value you don't get an error. The find just returns a span careless of the attributes that you need.
result.find("span", title=True)['title']
The code and html you provided are ambiguos. Your statement title = result.find("h2", {"class": "jobTitle"}) will never match the h2 tag because its class attribute is more complex, ``jobTitle jobTitle-color-purple jobTitle-newJob`. To match that you need
import re
...
result.find("h2", class_=re.compile(r'jobTitle'))
Use regular expression to improve the search in the soup.