A table in a database has the following data:
| index | item | height | width |
|---|---|---|---|
| 0 | A | 5 | 1 |
| 1 | A | 6 | 1 |
| 2 | A | 7 | 1 |
| 0 | B | 55 | 8 |
| 1 | B | 66 | 8 |
| 2 | B | 77 | 8 |
With an SQL query it should be turned into:
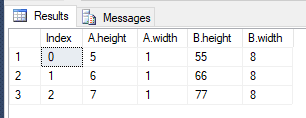
| index | A.height | A.width | B.height | B.width |
|---|---|---|---|---|
| 0 | 5 | 1 | 55 | 8 |
| 1 | 6 | 1 | 66 | 8 |
| 2 | 7 | 1 | 77 | 8 |
There can be, at the time of writing the SQL query, an unknown number of different items (A,B,C,D,...), and the new columns should be generated accordingly (... D.height, D.width ...).
What would be the best approach to do this in SQL?
The goal is to
- have a continuous
indexcolumn without duplicates, and - query a slice of the data by using the
index(e.g. WHERE index BETWEEN 1 AND 6), and - have all the data returned with one query
- (and, of course, not modify the original table)
CodePudding user response:
What you are looking for is a Dynamic PIVOT which requires Dynamic SQL.
There are many examples, but I get the sense you need a nudge.
Example
Declare @SQL varchar(max) = '
Select *
From (
select [Index]
,B.*
From yourtable A
Cross Apply ( values ( concat(item,''.height''),height)
,( concat(item,''.width'' ),width )
)B(Item,Value)
) src
Pivot ( max(value) for Item in (' stuff((select Distinct ',' QuoteName(concat(item,'.height')) ',' QuoteName(concat(item,'.width')) From yourtable Order By 1 For XML Path('')),1,1,'') ') ) pvt
'
Exec(@SQL)
Results
EDIT: The Generated SQL Looks like this
Select *
From (
select [Index]
,B.*
From yourtable A
Cross Apply ( values ( concat(item,'.height'),height)
,( concat(item,'.width' ),width )
)B(Item,Value)
) src
Pivot ( max(value) for Item in ([A.height],[A.width],[B.height],[B.width]) ) pvt