I have an existing model that was trained on Azure. I want to fully integrate and start using the model on Databricks. Whats the best way to do this? How can I successfully load the model into databricks model workflow? I have the model in a pickle file
I have read almost all the documentation on databricks, but 99% of it is regarding new models trained on databricks and never about importing existing models.
CodePudding user response:
Since MLFlow has a standardized 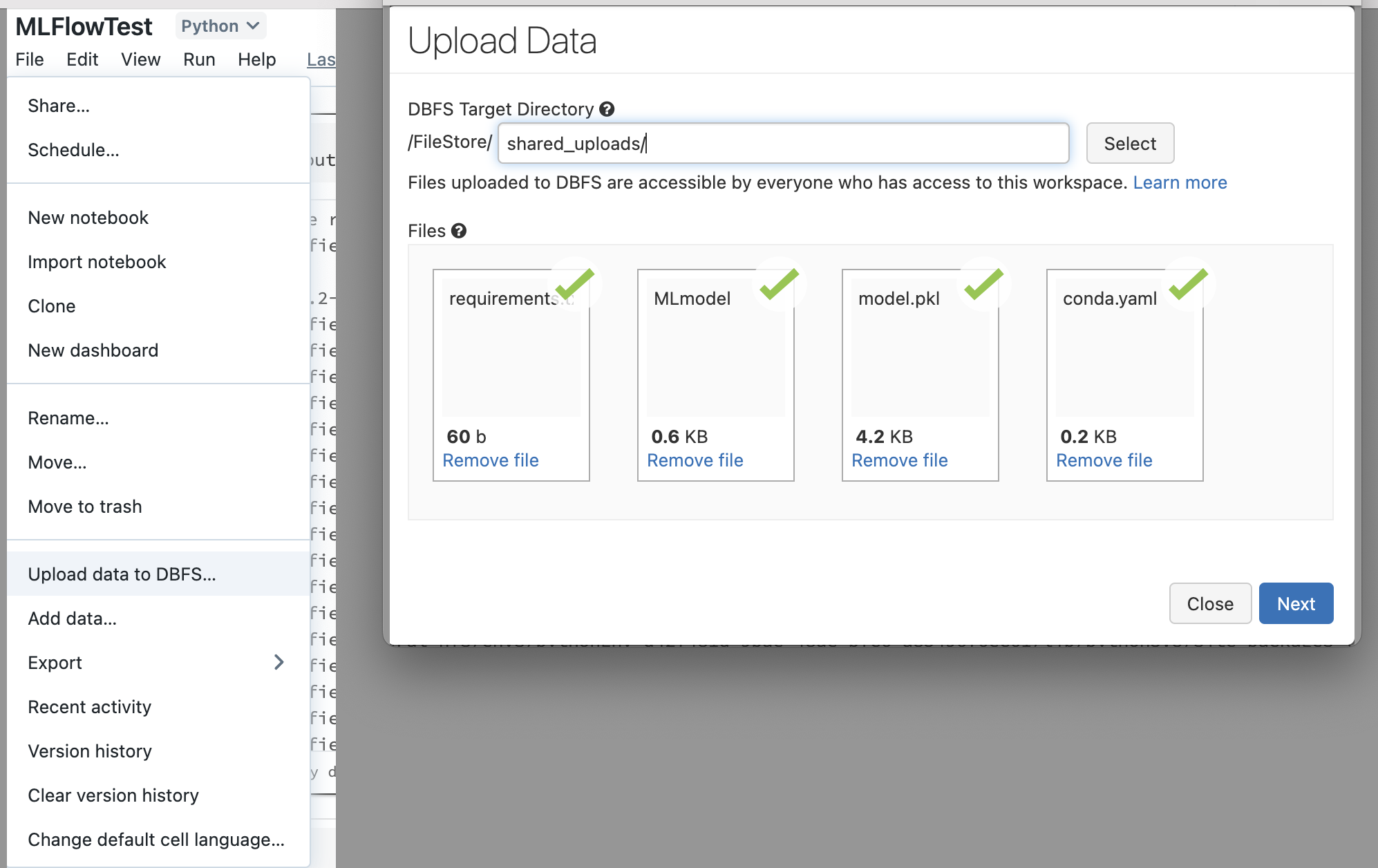
In the Notebook, register the model using MLFlow (adjust the dbfs: path to the location where the model was uploaded to).
import mlflow
model_version = mlflow.register_model("dbfs:/FileStore/shared_uploads/mlflow-model/", "AzureMLModel")
Now your model is registered in the Workspace's model registry like any model that was created from a Databricks session. So, you can access it from the registry like so:
model = mlflow.pyfunc.load_model(f"models:/AzureMLModel/{model_version.version}")
input_example = {
"sepal_length": [5.1,4.8],
"sepal_width": [3.5,4.4],
"petal_length": [1.4,2.0],
"petal_width": [0.2,0.1]
}
model.predict(input_example)

Or use the model as a spark_udf:
import pandas as pd
model_udf = mlflow.pyfunc.spark_udf(spark=spark, model_uri=f"models:/AzureMLModel/{model_version.version}", result_type='string' )
spark_df = spark.createDataFrame(pd.DataFrame(input_example))
spark_df = spark_df.withColumn('foo', model_udf())
display(spark_df)
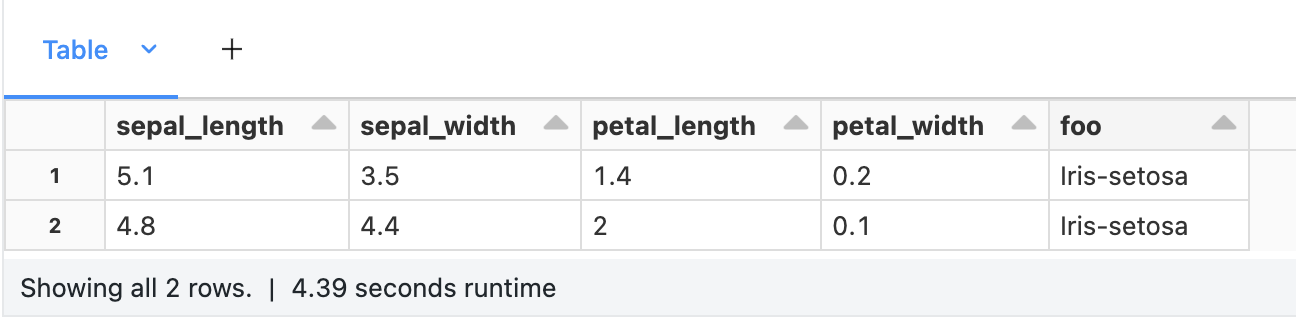
Note that I am using
mlflow.pyfuncto load the model since every MLFlow model needs to support thepyfuncflavor. That way, you don't need to worry about the native flavor of the model.
CodePudding user response:
- If your source model is already in a MLflow tracking server.
https://github.com/mlflow/mlflow-export-import
- If your source model was not trained in MLflow.
How do I create an MLflow run from a model I have trained elsewhere?