I have a dataframe that looks like the following:
df = pd.DataFrame({'ID': ['1', '1', '1', '2', '2', '2'],
'ID2': ['25', '29', '56', '562', '92', '170'],
'Origin': ['2005', '2010', '2020', '1995', '1999', '2007'],
'Status' : ['Done', 'Unfinished', 'Done', 'Done', 'Done', 'Unfinished']
})
df
---- ----- -------- ------------
| ID | ID2 | Origin | Status |
---- ----- -------- ------------
| 1 | 25 | 2005 | Done |
| 1 | 29 | 2010 | Unfinished |
| 1 | 56 | 2020 | Done |
| 2 | 562 | 1995 | Done |
| 2 | 92 | 1999 | Done |
| 2 | 170 | 2007 | Unfinished |
---- ----- -------- ------------
I am trying to separate into groups based on ID and update the Status column from Unfinished to Done if there is another row in the same group with a newer Done value. Essentially, if the Unfinished row is the most recent within the group, then leave the same. If Unfinished is not the most recent, change to Done.
Sample output below:
---- ----- -------- ------------ ----------------
| ID | ID2 | Origin | Status | Updated_Status |
---- ----- -------- ------------ ----------------
| 1 | 25 | 2005 | Done | |
| 1 | 29 | 2010 | Unfinished | Done |
| 1 | 56 | 2020 | Done | |
| 2 | 562 | 1995 | Done | |
| 2 | 92 | 1999 | Done | |
| 2 | 170 | 2007 | Unfinished | |
---- ----- -------- ------------ ----------------
After I finish df.groupby('ID') I know I have to try some variation of
df.loc[(df['Status'] == 'Unfinished') & (df['Origin'] > today.year)] but I can't think of the proper logic or syntax to properly adjust this dataframe.
All help appreciated.
CodePudding user response:
I think you can test if shifted values per groups by 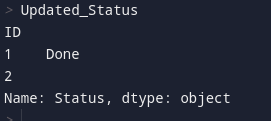
Must add this to the dataframe,,
CodePudding user response:
It is as simple as
mask = (df.groupby('ID')['Status'].transform('last') == 'Done') & (df.Status == 'Unfinished')
df['Updated_Status'] = np.where(mask, 'Done', np.nan)
The last row in each group corresponds to the latest entry. Use that to transform for each Status. Then, use the condition for updating the status.