I am trying to write a program which will be appending selected column of a csv file to another csv file as a row.
I have this code:
def append_pandas(s,d):
import pandas as pd
df = pd.read_csv(s, sep=';', header=None)
df_t = df.T
df_t.columns = df_t.iloc[0]
df_new = df_t.drop(0)
pdb = pd.read_csv(d, sep=';')
newpd = pdb.append(df_new)
newpd.to_csv(d)
Which does the job only with the first file, like this:
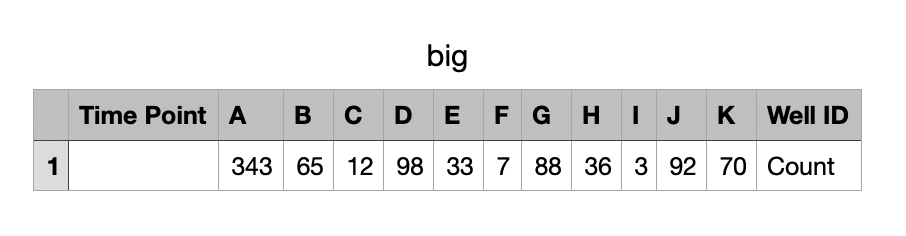
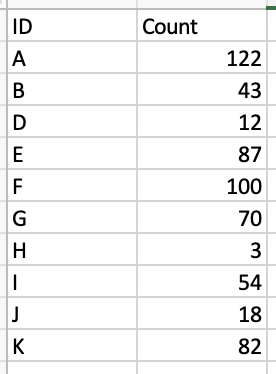
It is exactly what I want. But when the next file is added, this is what happens:

And the following file:

I am pretty confused. How to make them being aligned row by row?.. Please, help :(
P.S. My initial csv file is in this format (that's why I need to select a particular column - Cell Count):
CodePudding user response:
Because at one time, you save newpd using the default separator ',' (by not specifying a separator), and the next time when you read it back, you read it with the separator ';' which is ofcourse not correct because it is supposed to be ','.
A fix would be to always use ';' as your separator, so you need to do to_csv like this
newpd.to_csv(d, sep=';')
If you want to use ',' for your combined dataframe, you just need to be careful on when to read on separator ';' and when ','.
Second approach
If files is the list of file paths to all of your csv files that you want to combine, you can actually do this
newpd = pd.concat([pd.read_csv(file, sep=';').set_index('ID').T for file in files])
newpd.to_csv('name.csv', sep=',') # or ';'
Here you read each file, set 'ID' as the index, .T to make index become header, and finally concatenate all the resulting dataframes into one, and save it!