I have this code in R where I am using data.table, and I have the intention to translate it into Python with datatable. It creates columns with the value of each existing column divided by the mean of the total. Kind of normalization.
dataset[ , paste0( cols, suffix) := lapply( .SD, function(x){ x/mean(x, na.rm=TRUE)} ),
by= col_A,
.SDcols= cols]
CodePudding user response:
from datatable import f,by,update,dt
dataset=dt.Frame({'col_A':[0,0,1,1], 'col_B':[1,2,3,4], 'col_C':[5,6,7,8]})
cols = dataset[:,[int,float]].names
dataset[:, update(**{col '_norm': f[col]/dt.mean(f[col]) for col in cols if col!='col_A'}), by(f.col_A)]
CodePudding user response:
According to the documentation, update function and del operator operate in-place. This may be done in a loop also if there are many columns
DT[:, update(y_suffix = f.y/dt.mean(f.y), v_suffix = f.v/dt.mean(f.v)), by("x")]
-output
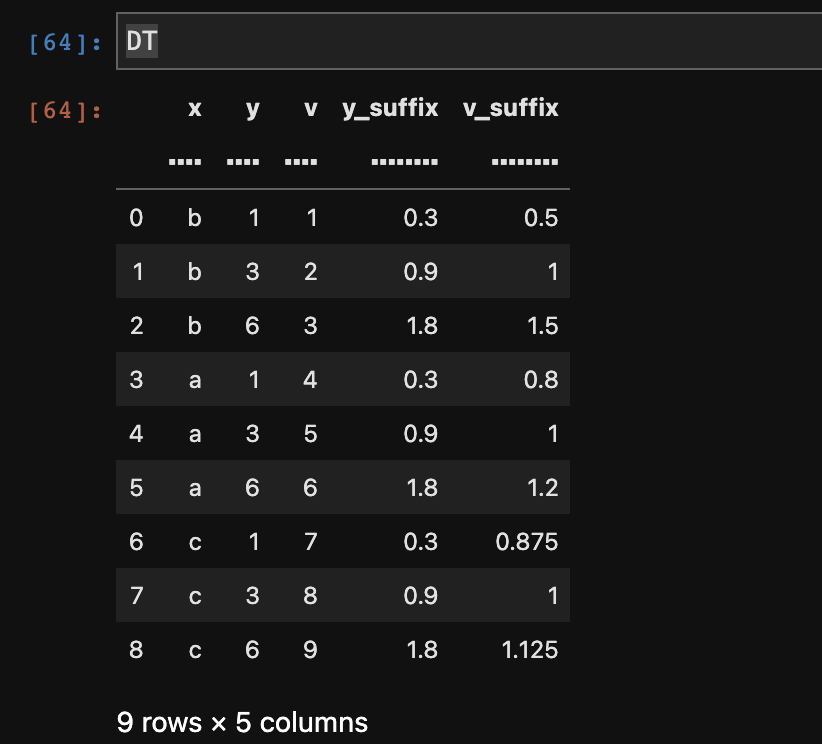
data
from datatable import dt, f, g, by, update
DT = dt.Frame(x = ["b"]*3 ["a"]*3 ["c"]*3,
y = [1, 3, 6] * 3,
v = range(1, 10))