I download 
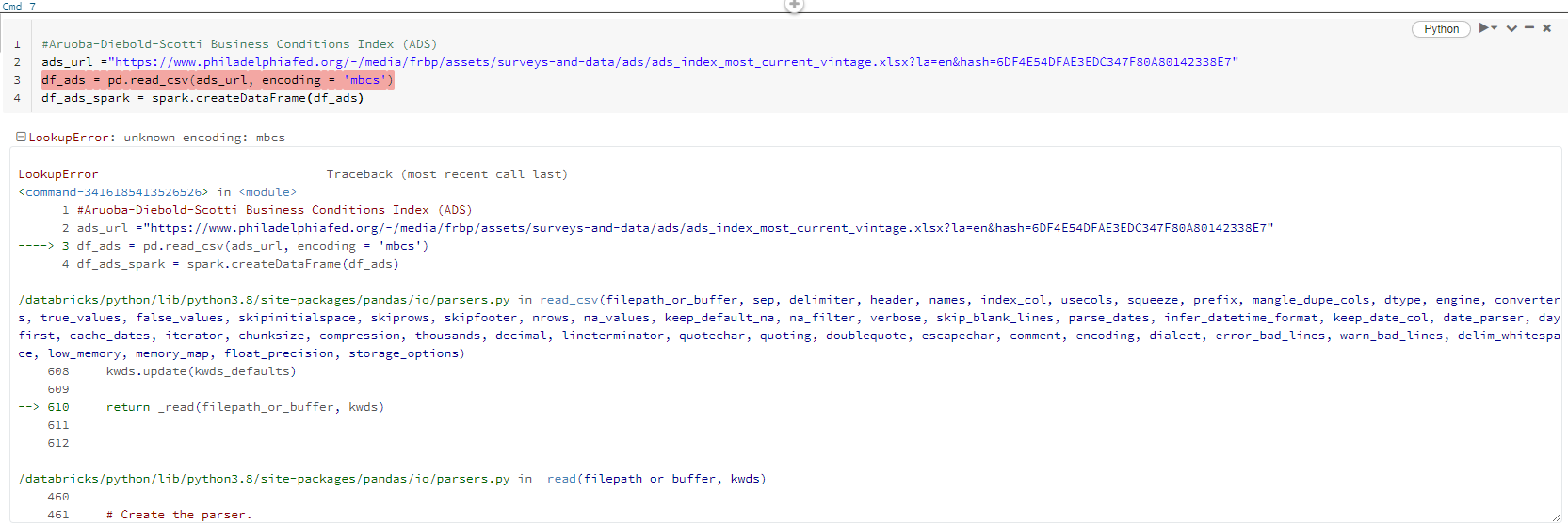
Therefore, I use encoding = 'mbcs' to decode it. However, there is an error unknown encoding: mbcs
Orginal Code:
ads_url ="https://www.philadelphiafed.org/-/media/frbp/assets/surveys-and-data/ads/ads_index_most_current_vintage.xlsx?la=en&hash=6DF4E54DFAE3EDC347F80A80142338E7"
df_ads = pd.read_csv(ads_url, encoding = 'mbcs')
df_ads_spark = spark.createDataFrame(df_ads)
CodePudding user response:
I’m not sure how you concluded you needed MBCS encoding to makes sense of the file but I believe the file is an Excel file. The .xlsx extension indicates it is a zip file (which explains why it’s unreadable in Notepad ) with parts representing the spreadsheet. You can read an .xlsx file in Databricks. No need to extract the zip file parts.
CodePudding user response:
After google searching, I find this one works. If you are required to install packages, please install them.
import urllib.request
import chardet
from urllib.parse import unquote
import requests
ads_url = "https://www.philadelphiafed.org/-/media/frbp/assets/surveys-and-data/ads/ads_index_most_current_vintage.xlsx?la=en&hash=6DF4E54DFAE3EDC347F80A80142338E7"
r = requests.get(ads_url)
open('ads_index_most_current_vintage.xlsx?la=en&hash=6DF4E54DFAE3EDC347F80A80142338E7', 'wb').write(r.content)
df_ads = pd.read_excel('ads_index_most_current_vintage.xlsx?la=en&hash=6DF4E54DFAE3EDC347F80A80142338E7')
df_ads_spark = spark.createDataFrame(df_ads)
display(df_ads_spark)