I'm working with twitter data using R. I have a large data frame where I need to remove everything from the text except from specific information. Specifically, I want to remove everything except from statistical information. So basically, I want to keep numbers as well as words such as "half", "quarter", "third". Also is there a way to also keep symbols such as "£", "%", "$"?
I have been using "gsub" to try and do this:
df$text <- as.numeric(gsub(".*?([0-9] ).*", "\\1", df$text))
This code removes everything except from numbers, however information regarding any words was gone. I'm struggling to figure out how I would be able to keep specific words within the text as well as the numbers.
Here's a mock data frame:
text <- c("here is some text with stuff inside that i dont need but also some that i do, here is a word half and quarter also 99 is too old for lego", "heres another one with numbers 132 1244 5950 303 2022 and one and a half", "plz help me with code i am struggling")
df <- data.frame(text)
I would like to be be able to end up with data frame outputting:
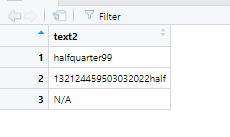
Also, I've included a N/A table in the picture because some of my observations will have neither a number or the specific words. The goal of this code is really just to be able to say that these observations contain some form of statistical language and these other observations do not.
Any help would be massively appreciate and I'll do my best to answer any Q's!
CodePudding user response:
I am sure there is a more elegant solution, but I believe this will accomplish what you want!
df$newstrings <- unlist(lapply(regmatches(df$text, gregexpr("half|quarter|third|[[:digit:]] ", df$text)), function(x) paste(x, collapse = "")))
df$newstrings[df$newstrings == ""] <- NA
> df$newstrings
# [1] "halfquarter99" "132124459503032022half" NA